ember بدأ كمسار cpu واضح: tensors بترتيب row-major، تحميل gguf، أوزان q8_0 تبقى مضغوطة، و trait للـ backend حول عمليات النموذج. الشغل الأحدث يحافظ على نفس الشكل. الـ SIMD ليس backend جديد، و qwen 3 / gemma 4 ليسوا تطبيقات منفصلة. هي إضافات ضيقة على نفس حلقة inference.
القيد المهم ممل لكنه مفيد: مسار prompt واحد، مسار probe واحد، وعقد kv-cache واحد. الشفرة الخاصة بكل architecture تدخل فقط في المكان الذي تختلف فيه عائلة النموذج فعلاً.
| ما الذي تغير؟ | q8_0 decode أخذ kernels SIMD؛ qwen 3 أخذ metadata خاصة بـ qwen و q/k norm؛ و gemma 4 أخذ مسار dense text منفصل. |
| لماذا يهم؟ | decode تهيمن عليه quantized linear layers، وعوائل النماذج الجديدة تحتاج نفس أدوات generation و probe. |
| أصعب جزء | إبقاء المسارات السريعة ضيقة: لا backend جديد، لا generation loop منفصلة، ولا probe pipeline مكرر. |
| ما بقي ثابتاً؟ | ForwardModel، تخزين q8_0، تحميل gguf، sampling، logits dump، واستخراج probes. |
| النتيجة | 8.2x تسريع في fused q8_0 decode ضمن benchmark الـ kernel، مع دعم qwen 3 و gemma 4 dense text-only من نفس cli. |
أوزان q8_0 مخزنة كـ blocks من ggml: بايتين scale بصيغة fp16 وبعدها 32 قيمة int8 موقعة. المسار scalar القديم كان يفك block إلى f32 ثم يضرب. مسار SIMD يبقي نفس layout ويغير الحلقات الداخلية فقط.
runtime dispatch موجود في src/simd.rs. على x86-64 يستخدم avx2 للتوسيع و fma للـ dot products. على aarch64 يستخدم neon. الأجهزة غير المدعومة تأخذ المسار scalar. مواقع الاستدعاء العامة تبقى في CpuBackend، فشفرة النموذج ما زالت تستدعي Linear::forward فقط.
| المسار | kernel | السبب |
|---|---|---|
| q8_0 row dequant | avx2 / neon / scalar | تحويل الصفوف المضغوطة إلى f32 بدون تغيير التخزين |
| single-token decode | fused q8_0 dot product | تفادي dense temporary وتكلفة sgemm |
| prefill | block dequant + sgemm | إعادة استخدام dense matrix multiply عندما صفوف prompt كثيرة تشارك الأوزان |
| elementwise ops | sum squares, add, elemul, weighted add | تسريع rms norm وتجميع attention وربط mlp |
مساحة unsafe صغيرة عمداً. الـ backend يتحقق من رتبة tensor والأبعاد الداخلية قبل استدعاء kernels q8_0؛ و QuantizedWeight::try_new يتحقق من block alignment وطول البايتات عند تحميل بيانات gguf خارجية. داخل kernels، unsafe مستخدم لأجل target-feature intrinsics و pointer loads، لا لأجل حيلة ملكية أوسع.
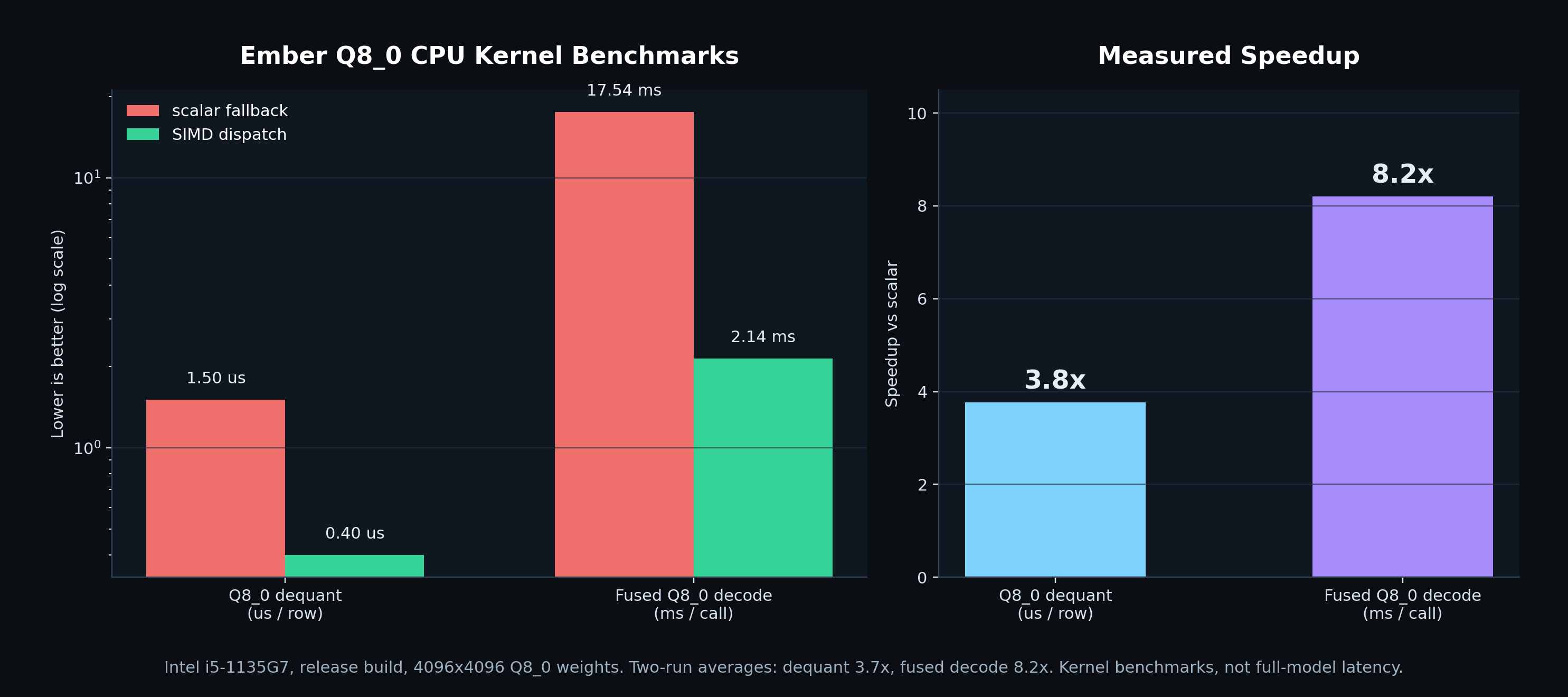
هذا benchmark هو سبب الأداء الأساسي وراء شغل SIMD. على intel i5-1135G7 في release build مع أوزان q8_0 بحجم 4096x4096، dispatch إلى kernels SIMD ينزل q8_0 row dequantization من 1.50 us إلى 0.40 us لكل صف، وينزل fused single-token decode من 17.54 ms إلى 2.14 ms لكل استدعاء. هذا 3.8x لفك التكميم الخام، و 8.2x لـ decode kernel الذي تضربه generation مع كل token جديد.
qwen 3 يمر عبر transformer عائلة llama في src/llama.rs. هذا التقسيم صحيح لأن الـ block ما زال rms norm، إسقاطات q/k/v منفصلة، rope، grouped query attention، و swiglu. الاختلافات في metadata و q/k normalization، وليس محرك تنفيذ جديد.
cargo run --release -- \
--arch qwen3 \
--model Qwen3-0.6B-Q8_0.gguf \
--tokenizer tokenizer-qwen3.json \
--prompt "اكتب جملة قصيرة"LlamaConfig::from_gguf_metadata يقرأ general.architecture ويبدل metadata prefix إلى qwen3.*. كذلك يحترم attention.key_length الصريح عندما يكون موجوداً، بدلاً من افتراض embedding_length / head_count. tensors attn_q_norm.weight و attn_k_norm.weight اختيارية لكل طبقة؛ عند وجودها، مسار attention يطبق rms normalization لكل head بعد rope وقبل attention.
النتيجة أن qwen 3 يستخدم نفس generation و logits dump و probe modes مثل llama. علم qwen-specific يعني غالباً: اختر tokenizer الافتراضي لـ qwen واقرأ metadata الخاصة به بدون ادعاء أن الملف llama.
gemma 4 له module خاص، src/gemma4.rs، لأن نموذج النص قريب من عائلة llama لكنه ليس مطابقاً. عنده طبقات attention محلية وعامة، إعدادات rope محلية/عامة منفصلة، final-logit softcapping اختياري، و per-layer input embeddings اختيارية. ضغط هذا داخل Llama كان سيجعل المسارين أصعب في القراءة.
cargo run --release -- \
--arch gemma4 \
--model models/gemma-4-E2B-it.Q8_0.gguf \
--tokenizer tokenizer-gemma4.json \
--prompt "اكتب جملة قصيرة"الهدف المدعوم هو gemma 4 dense text-only. الـ loader يرفض metadata الخاصة بـ moe، والـ cli ما زال يحصر demo و interactive mode في مسار gpt-2 الأقدم. generation و last-logit dump واستخراج probes تستخدم trait المشترك ForwardModel.
| الميزة | qwen 3 | gemma 4 |
|---|---|---|
| module | src/llama.rs | src/gemma4.rs |
| attention | مشابه لـ llama مع q/k norm اختياري | مزيج local/global attention مع sliding windows |
| rope | مسار rope لعائلة llama مع مفاتيح metadata الخاصة بـ qwen | إعدادات rope منفصلة للمحلي والعام |
| ما تغير | metadata prefix، head dim صريح، q/k rms norm | block type جديد، layer types، softcap، و PLE اختياري |
| ما بقي ثابتاً | generation، sampling، أوزان q8_0، واستخراج probes | generation، sampling، أوزان q8_0، واستخراج probes |
| الحد الصلب | افتراضات عائلة llama ما زالت تنطبق | dense text-only؛ لا moe ولا multimodal path |
| cli | --arch qwen3، tokenizer-qwen3.json | --arch gemma4، tokenizer-gemma4.json |
SIMD يغير السرعة بدون تغيير عقد النموذج. qwen 3 يغير metadata و attention normalization بدون تغيير قلب عائلة llama. gemma 4 يغير module الـ transformer، لكنه ما زال يطبق نفس سطح ForwardModel. هذه هي نقطة المعمارية: kernels جديدة وعوائل نماذج جديدة تدخل بدون إعادة كتابة generation أو sampling أو probing أو gguf loading من الصفر.