التغييرات الأخيرة في ember نقلت المشروع من مسار تشغيل ضيق إلى pipeline أوضح للتجارب. التركيز هنا على runtime، استخراج activations بشكل streamed، manifests للـ benchmarks، تقارير golden logits، smoke reports، وتقارير تدخل causal محافظة. الهدف ليس توسيع دعم النماذج فقط، بل جعل كل run أسهل في الإعادة والمراجعة.
| runtime | مساعدات CPU backend، إعادة استخدام scratch في q8_0، مسارات Rayon للـ attention، greedy sampling حتمي، واستخراج activations pooled. |
| artifacts | ملفات .npy streamed، metadata جانبية، smoke summaries، benchmark summaries، وتقارير Markdown. |
| validation | سكريبتات golden-logit وتصميم activation-reference checks. المراجع المستقلة ما زالت مطلوبة للادعاءات القوية. |
| research pipeline | metadata للـ split policies، manifests، استخراج encoder، MDL curves، وتقارير interventions محافظة. |
الـ CPU backend صار يحمل جزء أكبر من عقد التنفيذ: row helpers، scratch للـ q8_0 prefill، cached attention helpers، وRayon parallelism. هذا يقلل شغل hot path المتكرر بدون تغيير عقد النموذج العام. benchmark الـ SIMD موجود في صفحة SIMD/Qwen3/Gemma؛ القسم أدناه يقيس فقط سلوك thread counts بعد ذلك العمل.
probe extraction تغير أيضاً. بدلاً من dump كبير في الذاكرة، ember يكتب activation rows إلى .npy بشكل streamed ويسجل pooled per-layer states للمواقع المطلوبة. هذا يجعل سحب artifacts من السحابة أسهل من نقل activations الخام دائماً.
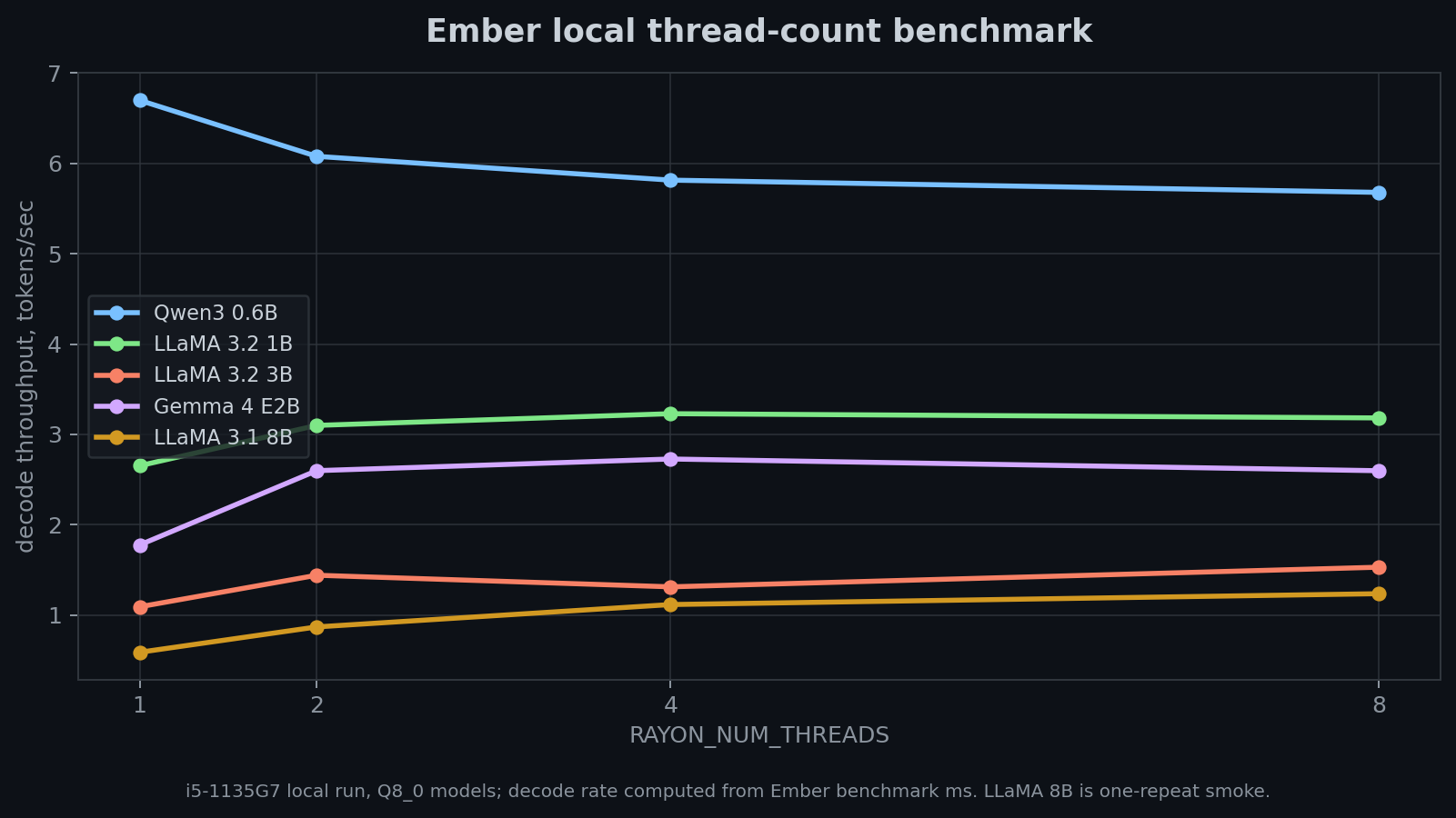
شغلت scripts/benchmark_threads.py محلياً على Intel i5-1135G7 مع 4 cores فعلية و8 hardware threads. كل الصفوف تستخدم GGUF من نوع Q8_0 وعداد decode من --benchmark داخل ember. كل thread count يعيد تحميل النموذج، لذلك wall time مفيد كسياق تشغيلي، أما الجدول فيستخدم decode milliseconds من benchmark output.
| model | repeats | 1 thread decode | best local decode | best threads | read |
|---|---|---|---|---|---|
| Qwen3 0.6B | 3 | 6.70 tok/s | 6.70 tok/s | 1 | لا يوجد gain محلي من threading في هذا التشغيل الصغير |
| LLaMA 3.2 1B | 2 | 2.63 tok/s | 3.23 tok/s | 4 | تحسن decode محدود |
| LLaMA 3.2 3B | 2 | 1.09 tok/s | 1.53 tok/s | 8 | تحسن decode أوضح محلياً |
| Gemma 4 E2B | 2 | 1.74 tok/s | 2.73 tok/s | 4 | أفضل thread count محلي لم يكن الأعلى |
| LLaMA 3.1 8B | 1 | 0.59 tok/s | 1.24 tok/s | 8 | smoke result اتجاهي فقط |
الاستنتاج المحافظ ضيق: على هذا الجهاز، النماذج الأكبر dense Q8_0 استفادت من مسارات threading، بينما Qwen3 0.6B الصغير لم يستفد. هذا لا يتنبأ بسرعة محددة على cloud؛ فقط يوضح أن threading له أثر محلي قابل للقياس عندما يكون النموذج كبيراً بما يكفي لتعويض overhead.
جهة Python صارت أوضح: run_benchmark.py يشغل jobs من manifest، وbenchmark_summary.py يسجل حالة artifacts، وrender_benchmark_report.py يحول summary إلى Markdown. لغة التقرير تتكلم عن decodability وحالة artifacts، وليس conclusions علمية.
تدريب probes صار يسجل split policies بشكل أوضح. random stratified موجود، لكن root-heldout وpattern-heldout وcombination-heldout وsentence-heldout وtemplate-heldout يمكن تسجيلها. إذا كان الحقل المطلوب غير موجود، يفشل الطلب بدلاً من الرجوع بصمت إلى random.
smoke reports تسجل سياق الجهاز والأوامر. golden-logit reports يمكن تلخيصها إلى JSON وMarkdown. تقارير causal intervention أيضاً تنتج Markdown، لكن تفسيرها ضيق: إزالة اتجاه probe قد تؤثر على decodability، أما behavioral causality فتحتاج تغير logits أو continuations.
activation-reference checks هي الخطوة المهمة التالية. golden logits تتحقق من سطح الخرج، لكن hidden-state probing يحتاج مقارنة طبقة بطبقة لنفس prompt وtokenizer وmodel وlayer وtoken position قبل اعتبار geometry ممثلة عددياً بشكل موثوق.
صفحة ember الرئيسية صارت تفصل engineering عن research/results. صفحة SIMD/Qwen3/Gemma تشرح التغييرات الضيقة في runtime ودعم عائلات النماذج. أما تفسير Arabic morphology فيبقى في research notes، ومعه يجب ربط أي claim بالأدلة الموجودة فعلاً.
أكثر عمل مفيد الآن هو العمل الممل: golden-logit references مستقلة لـ Qwen3 وLLaMA، activation reference check لنموذج صغير وprompt واحد، تقارير encoder benchmarks كاملة، compact cloud artifacts، وتنظيف أي نص قديم يبالغ فيما تم التحقق منه.