the recent ember work moved the project from "model support works in a narrow demo" toward an inspectable research pipeline. the main changes are runtime plumbing, streamed activation extraction, benchmark manifests, golden-logit summaries, smoke reports, and conservative causal-intervention reporting. the point is not broader model coverage for its own sake; it is making every run easier to reproduce, compare, and distrust productively.
| runtime | CPU backend helpers, q8_0 scratch reuse, Rayon attention paths, deterministic greedy sampling, and pooled activation extraction. |
| artifacts | streamed .npy activation files, sidecar metadata, smoke summaries, benchmark summaries, and Markdown reports. |
| validation | golden-logit comparison scripts and activation-reference design docs, with independent references still required for strong claims. |
| research pipeline | split-policy metadata, benchmark manifests, encoder extraction, MDL curves, and conservative intervention summaries. |
the CPU backend now carries more of the execution contract. row helpers, q8_0 prefill scratch, cached attention helpers, and Rayon parallelism reduce repeated hot-path work without changing the public model contract. the SIMD kernel benchmark is covered in the separate SIMD/Qwen3/Gemma page; the local benchmark below is only about post-SIMD thread-count behavior.
probe extraction also changed shape. instead of treating probe mode as a large in-memory dump, ember streams activation rows to .npy and records pooled per-layer states for the selected token positions. that makes cloud pullback and repeated benchmark runs less dependent on raw activation transfer.
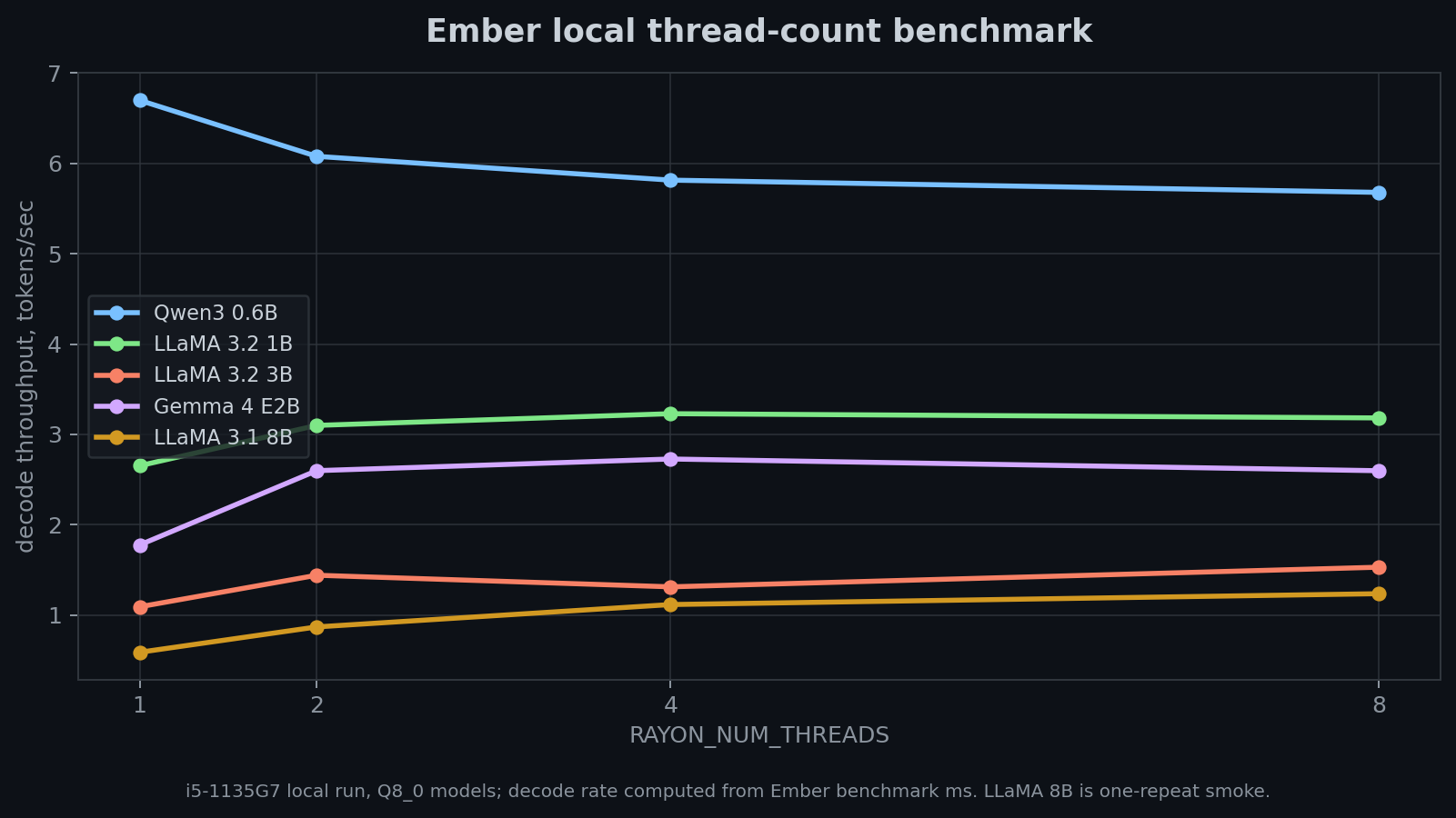
i ran scripts/benchmark_threads.py locally on an Intel i5-1135G7 laptop CPU with 4 physical cores and 8 hardware threads. all rows use Q8_0 GGUF files and Ember's own --benchmark decode timer. the runs reload the model for each thread count, so wall time is useful operational context, but the table below uses decode milliseconds from the benchmark output.
| model | repeats | 1 thread decode | best local decode | best threads | read |
|---|---|---|---|---|---|
| Qwen3 0.6B | 3 | 6.70 tok/s | 6.70 tok/s | 1 | no local threading gain in this small run |
| LLaMA 3.2 1B | 2 | 2.63 tok/s | 3.23 tok/s | 4 | modest decode improvement |
| LLaMA 3.2 3B | 2 | 1.09 tok/s | 1.53 tok/s | 8 | clearer local decode improvement |
| Gemma 4 E2B | 2 | 1.74 tok/s | 2.73 tok/s | 4 | best local thread count was not the maximum |
| LLaMA 3.1 8B | 1 | 0.59 tok/s | 1.24 tok/s | 8 | directional smoke result only |
the careful conclusion is narrow: on this machine, larger dense Q8_0 models benefited from the threaded runtime paths, while the small Qwen3 0.6B run did not. this does not predict a specific cloud speedup; it only says the threading work has measurable local effect once the model is large enough for the overhead to pay back.
the Python side now has a clearer benchmark surface: run_benchmark.py runs manifest-defined jobs, benchmark_summary.py records artifact status, and render_benchmark_report.py turns summaries into human-readable Markdown. the report language is intentionally about decodability and artifact status, not scientific conclusions.
probe training gained stricter split-policy handling for grouped experiments. random stratified splits still exist, but root-heldout, pattern-heldout, root-pattern combination-heldout, sentence-heldout, and template-heldout policies can now be recorded instead of being implicit. requested grouped splits fail when the required field is missing; they do not silently fall back to random.
smoke reports now record more of the machine and command context. golden-logit reports can be summarized into compact JSON and Markdown. causal-intervention reports can also render Markdown, but their interpretation is deliberately narrow: probe-direction removal can affect decodability, while behavioral causality requires changed logits or continuations.
the activation-reference design doc is the next important validation step. golden logits say the output surface matches a reference for a prompt. hidden-state probing also needs layer-by-layer activation checks for the same prompt, tokenizer, model, layer, and token position before treating representational geometry as numerically validated.
the docs were split into clearer lanes. the main ember page now separates engineering from research/results. the SIMD/Qwen3/Gemma page explains narrow runtime and model-family changes. the research notes remain responsible for Arabic morphology interpretation, and those claims should stay tied to actual validation artifacts.
the most useful next work is boring: independent golden-logit references for Qwen3 and LLaMA, activation reference checks for one small model and one prompt, full encoder benchmark reports, compact cloud artifact pullback, and continued cleanup of stale docs that overstate what has been validated.