ember started as a clean cpu path: row-major tensors, gguf loading, q8_0 weights kept compressed, and a backend trait around the model operations. the newer work keeps that shape. simd is not a new backend, and qwen 3 / gemma 4 are not separate applications. they are narrow additions to the same inference loop.
the important constraint is boring but useful: one prompt path, one probe path, one kv-cache contract. architecture-specific code should enter only where the model family actually differs.
| what changed? | q8_0 decode got simd kernels; qwen 3 gained qwen metadata + q/k norm; gemma 4 gained a separate dense text model path. |
| why did it matter? | decode is dominated by quantized linear layers, and new model families need the same generation and probe tooling. |
| hard part | keep fast paths narrow: no new backend, no forked generation loop, no duplicated probe pipeline. |
| same contract | ForwardModel, q8_0 storage, gguf loading, sampling, logits dump, and probe extraction stay shared. |
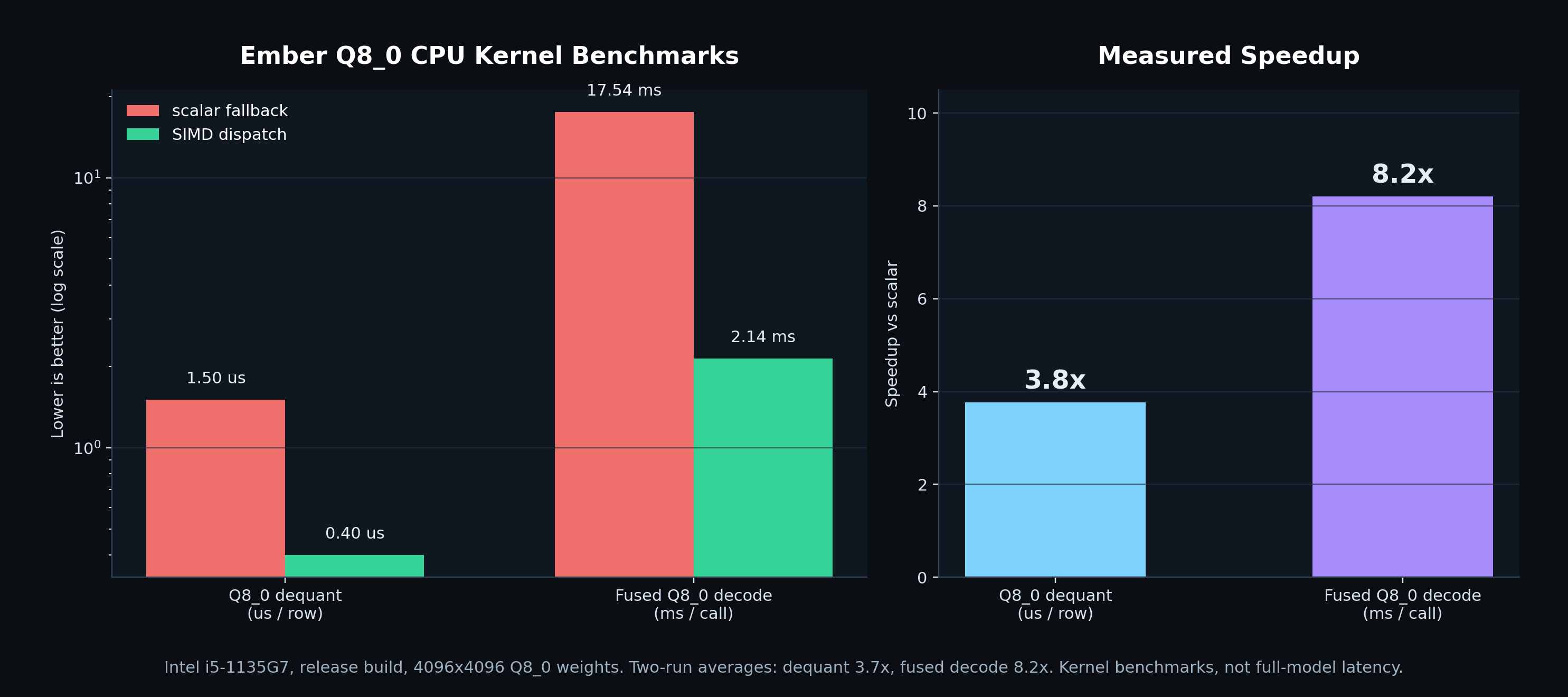
| result | 8.2x fused q8_0 decode speedup in the kernel benchmark, plus qwen 3 and dense text-only gemma 4 support through the existing cli. |
q8_0 weights are stored as raw ggml blocks: two bytes of fp16 scale followed by 32 signed int8 values. the old scalar path dequantized a block into f32, then multiplied. the simd path keeps the same layout and changes only the inner loops.
runtime dispatch lives in src/simd.rs. x86-64 uses avx2 for widening and fma for dot products. aarch64 uses neon. unsupported machines take the scalar fallback. the public call sites stay in CpuBackend, so model code still just calls Linear::forward.
| path | kernel | why it exists |
|---|---|---|
| q8_0 row dequant | avx2 / neon / scalar | turn compressed rows into f32 without changing storage |
| single-token decode | fused q8_0 dot product | avoid a dense temporary and sgemm overhead |
| prefill | block dequant + sgemm | reuse dense matrix multiply when many prompt rows share weights |
| elementwise ops | sum squares, add, elemul, weighted add | speed up rms norm, attention accumulation, and mlp glue |
the unsafe surface is intentionally small. the backend validates tensor rank and inner dimensions before calling the q8_0 kernels; QuantizedWeight::try_new checks block alignment and byte length when external gguf data is loaded. inside the kernels, unsafe is used for target-feature intrinsics and pointer loads, not for a broader ownership trick.
this benchmark is the core performance reason for the simd work. on an intel i5-1135G7 release build with 4096x4096 q8_0 weights, dispatching to the simd kernels drops q8_0 row dequantization from 1.50 us to 0.40 us per row, and the fused single-token decode call from 17.54 ms to 2.14 ms. that is 3.8x for raw dequantization and 8.2x for the decode kernel that generation hits every new token.
qwen 3 runs through the llama-family transformer in src/llama.rs. that is the right split because the block is still rms norm, separate q/k/v projections, rope, grouped query attention, and swiglu. the differences are metadata and q/k normalization, not a new execution engine.
cargo run --release -- \
--arch qwen3 \
--model Qwen3-0.6B-Q8_0.gguf \
--tokenizer tokenizer-qwen3.json \
--prompt "اكتب جملة قصيرة"LlamaConfig::from_gguf_metadata reads general.architecture and switches the metadata prefix to qwen3.*. it also honors explicit attention.key_length when present, instead of assuming embedding_length / head_count. per-layer attn_q_norm.weight and attn_k_norm.weight tensors are optional; when present, the attention path applies rms normalization per head after rope and before attention.
the result is that qwen 3 can use the same generation, logits dump, and probe modes as llama. the qwen-specific flag mostly says: choose the qwen tokenizer default and read qwen metadata without pretending the file is llama.
gemma 4 gets its own module, src/gemma4.rs, because its text model is close to the llama family but not identical. it has local and global attention layers, separate local/global rope settings, optional final-logit softcapping, and optional per-layer input embeddings. squeezing that into Llama would make both paths harder to reason about.
cargo run --release -- \
--arch gemma4 \
--model models/gemma-4-E2B-it.Q8_0.gguf \
--tokenizer tokenizer-gemma4.json \
--prompt "اكتب جملة قصيرة"the supported target is dense text-only gemma 4. the loader rejects moe metadata, and the cli still keeps demo and interactive mode limited to the older gpt-2 path. generation, last-logit dump, and probe extraction use the shared ForwardModel trait.
| feature | qwen 3 | gemma 4 |
|---|---|---|
| module | src/llama.rs | src/gemma4.rs |
| attention | llama-like attention with optional q/k norm | local/global attention mix with sliding windows |
| rope | shared llama-family rope path with qwen metadata keys | separate local and global rope settings |
| what changed | metadata prefix, explicit head dim, q/k rms norm | new block type, layer types, softcap, optional PLE |
| what stayed same | generation, sampling, q8_0 weights, probe extraction | generation, sampling, q8_0 weights, probe extraction |
| hard boundary | llama-family assumptions still apply | dense text-only; no moe or multimodal path |
| cli | --arch qwen3, tokenizer-qwen3.json | --arch gemma4, tokenizer-gemma4.json |
simd changes speed without changing the model contract. qwen 3 changes metadata and attention normalization without changing the llama-family core. gemma 4 changes the transformer module, but still implements the same ForwardModel surface. that is the point of the architecture: new kernels and new model families can land without rewriting generation, sampling, probing, or gguf loading from scratch.