the Alakeel et al. (2026) paper left an open question: GPT-4o gets 97% on nonce Arabic root-pattern generation despite having the worst tokenizer alignment in the study (17% boundary precision). ALLAM, with the best tokenizer alignment, collapses to 20% on the same task. tokenizer quality doesn't predict morphological competence , so what does?
the authors suggested "compositional reasoning + instruction-following" as the mechanism. but that's a behavioral description. this experiment asks the mechanistic question: what do the internal representations actually look like?
i used ember, a from-scratch inference engine that gives direct access to hidden states at every transformer block, to probe LLaMA 3.2 1B and LLaMA 3.2 3B on a nonce root-pattern task. 20 invented triliteral roots (from the Alakeel dataset) crossed with 10 Arabic morphological patterns = 200 stimuli, all Latin-transliterated for ASCII-safe probing. 8B results from the first pass are archived below as stale until they can be rerun off-machine. four analysis methods:
a note on method: probes measure what information is recoverable from hidden states, not what the model causally uses during generation. linear separability is a lower bound on the structure present; it does not imply the model relies on that structure for its outputs. the corrected runs use task-specific closed-set splits: root probes hold out patterns, and pattern probes hold out roots. the old root-held-out root probe framing was invalid because it asked a classifier to predict unseen root labels.
the rerun 1B and 3B models still output "The" for every stimulus: 0/200. the hidden states preserve the explicit root and pattern variables from the prompt, but this is not yet proof of internal Arabic morphology. the next controls need to separate prompt-variable recovery from actual morphological computation.
generate_stimuli.py → stimuli/nonce_root_pattern.json (200 stimuli)
ember --probe → activations.npy + correctness.json
train_linear_probe.py → probes.npz (root + pattern accuracy per layer)
cca_analysis.py → cca.npz (layer similarity + disentanglement)
rsa_analysis.py → rsa.npz (representational similarity)
divergence_analysis.py → divergence.npz (correct vs incorrect gap)
plot_results.py --dark → probe_results.png (3x2 figure)
all code is in the ember repository. the corrected 1B and 3B reruns were done locally. the 8B first-pass plot remains shown as an archived comparison, but it was not rerun with the corrected split logic because the local machine cannot run it reliably.
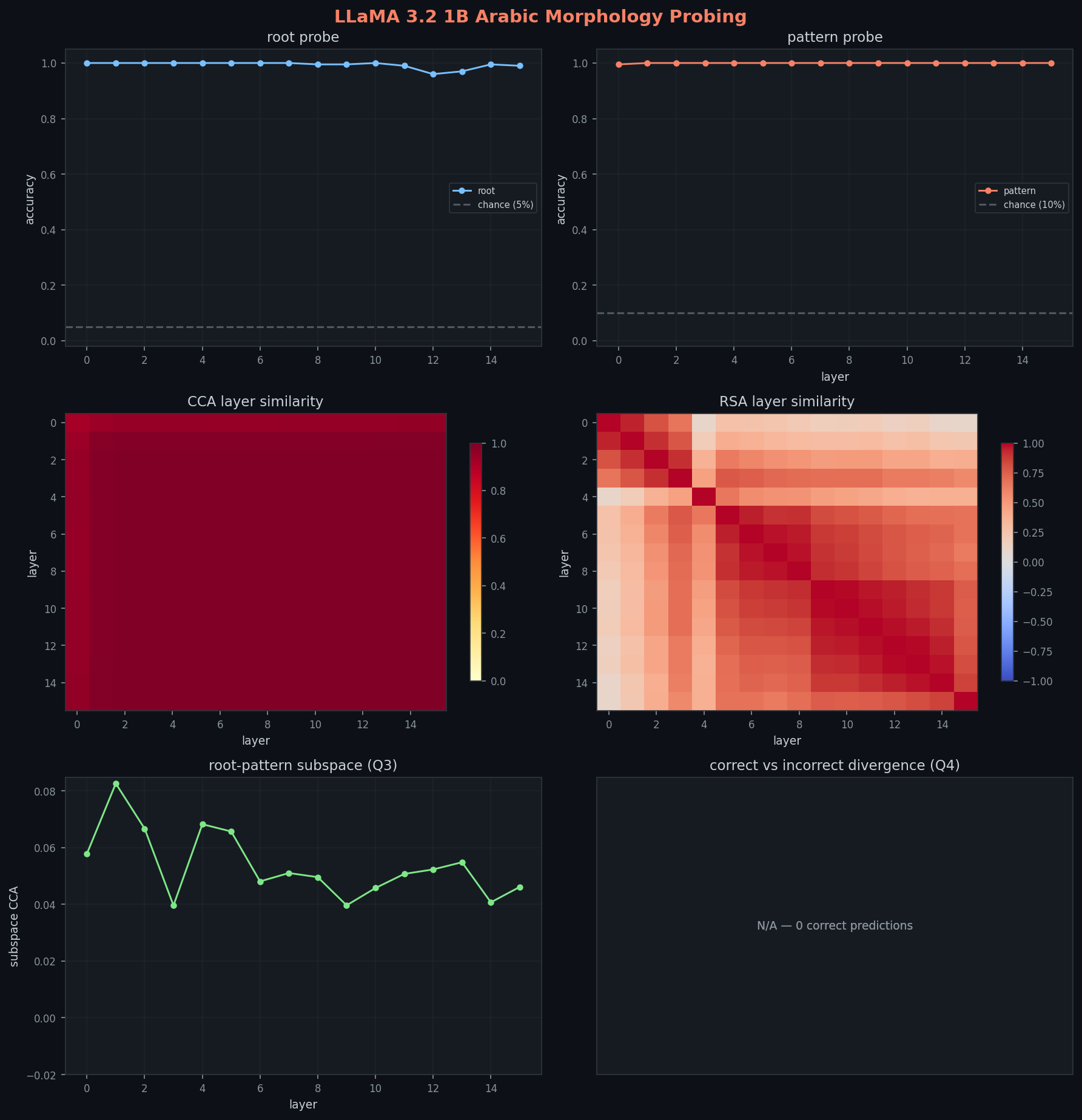
root identity is trivially decodable at every layer (96-100% accuracy, nearly flat curve). root information remains linearly recoverable across the full depth of the model.
pattern identity is already linearly decodable at layer 0 under the corrected root-held-out split: 99.5% at layer 0 and 100% after that. the old "pattern acquisition curve" does not survive the corrected split logic.
CCA self-similarity starts at 0.92 (layer 0) and saturates rapidly (0.98 by layer 1, 0.999 by layer 4). representations stabilize fast. RSA still shows an early geometric transition, but it should no longer be explained as the moment pattern first becomes recoverable.
root-pattern subspace CCA is low from the start in the corrected probe setup, roughly 0.04-0.08 across layers, with a minimum of 0.040 at layer 3. root and pattern probe weights are already strongly separated.
this is where things get strange.
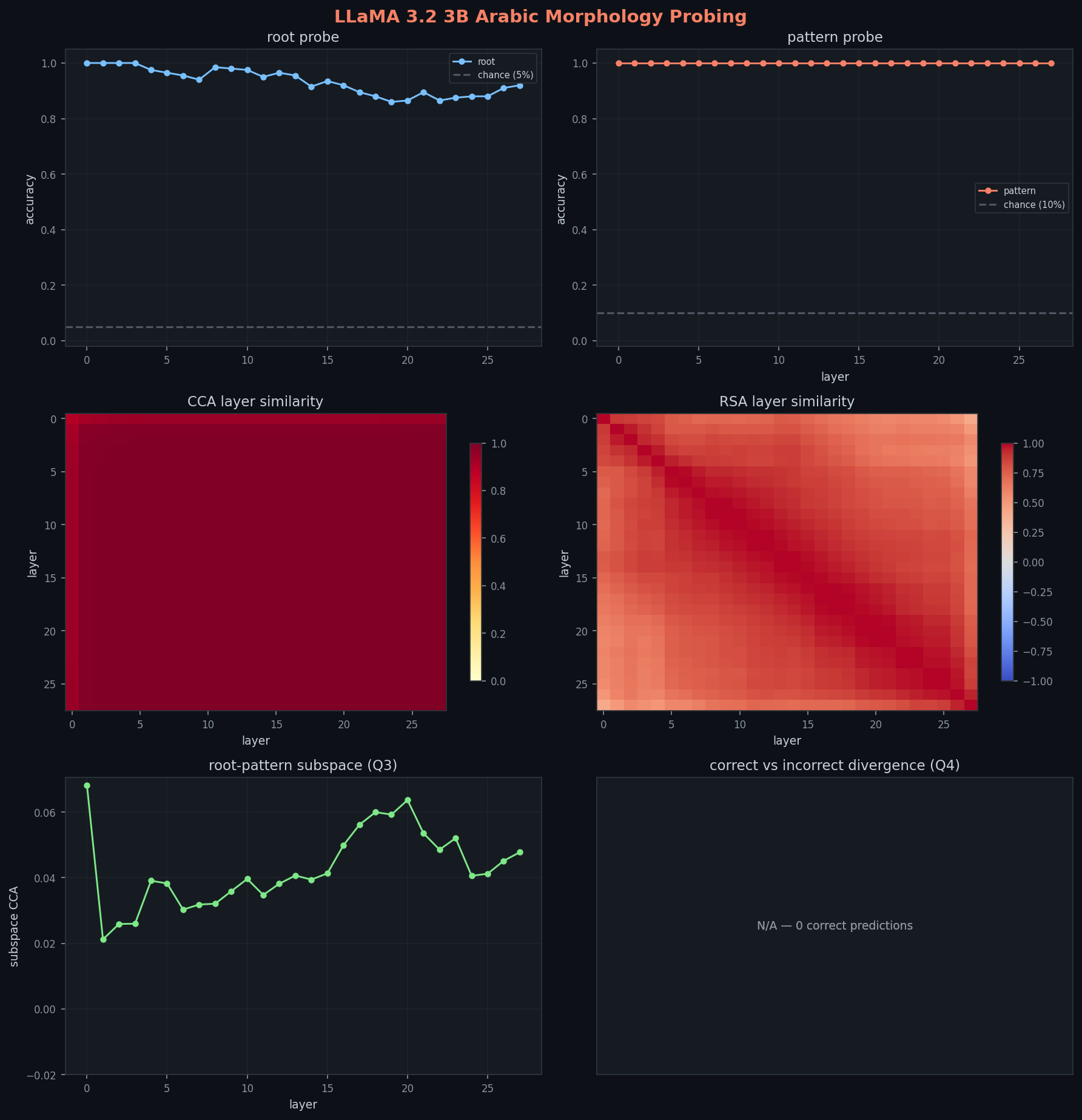
root identity still develops a U-shaped dip, but the corrected trough is weaker than the first write-up claimed. it starts at 100%, erodes across mid-layers, bottoms at 86% at layer 19, then partially recovers to 92% in the final layer. root identity becomes less linearly accessible in mid-layers before partially returning in the deepest blocks.
pattern identity is dead flat at 100% for all 28 layers. pattern is linearly separable as a surface-level feature , no depth required to separate the 10 pattern classes linearly. the 3B model shows pattern identity on a linearly accessible subspace from the first layer onward.
CCA self-similarity starts at 0.889 at layer 0 (slightly lower than 1B's 0.921) but stabilizes faster: 0.977 by layer 1, 0.995 by layer 3. the heatmap is essentially uniform bright yellow from layer 4 onward. RSA shows smooth, continuous transitions with no sharp break like 1B's layer 3–4 drop.
root-pattern CCA is very low in the corrected run: 0.02-0.07 across all layers, minimum 0.021 at layer 1. the probe weight subspaces for root and pattern appear nearly orthogonal under CCA at every layer.
3B still has the clearest root dip. After correcting the split logic, 1B no longer shows a pattern acquisition curve. Both 1B and 3B have pattern identity essentially available from layer 0. The robust 3B-specific result is the root dip: root identity is still recoverable, but less linearly accessible in the middle of the network. The model still has no Arabic output to show for it.
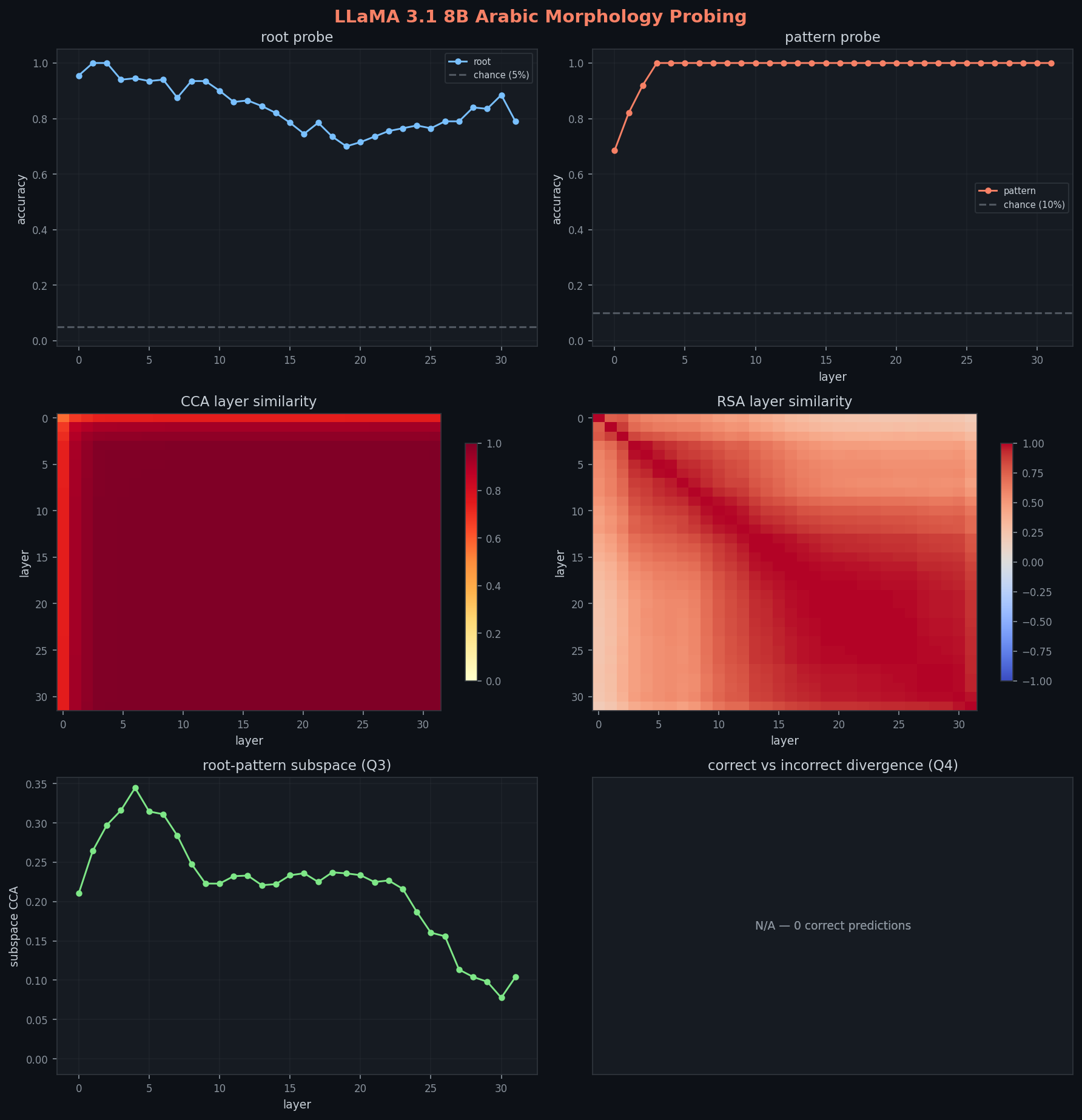
archival caveat: this 8B section uses the first-pass probe files and has not been rerun with the corrected split logic. do not compare its exact numbers to the corrected 1B/3B results yet.
root identity appeared to deepen the U-dip: after a brief peak at 100% (layer 1), it descends through 94% → 88% → 75% → bottoms at 70% at layer 19, partially recovers to 89%, then drops again to 79% at the final layer. the curve is textured, not a clean U, with a jagged descent and a secondary dip at the end. treat this as an archived signal, not a corrected scaling conclusion.
pattern identity appeared to return to a staircase in the archived run: 69% at layer 0 -> 82% -> 92% -> 100% by layer 3. because the corrected 1B result changed substantially, this 8B pattern claim should be treated as pending rerun.
CCA starts dramatically lower: 0.566 at layer 0 , the noisiest early representation of any model. then climbs: 0.68 (layer 1) → 0.94 (layer 2) → 0.99 (layer 4). the heatmap has a visibly dark bottom-left corner that brightens across the first 4 layers. RSA layer 0→1 correlation is 0.76, then smooth 0.96–0.999 thereafter.
root-pattern CCA shows the most interesting curve: it rises to a peak of 0.345 at layer 4 , the probe subspaces briefly show higher overlap , then steadily declines to 0.078 at layer 30. this is a pattern consistent with early representational mixing followed by later separability: the first few layers show increased subspace overlap between root and pattern probe weights, while deeper layers show increasingly separable organization. neither 1B (monotonic decline) nor 3B (flat-near-zero) shows this two-phase pattern.
root probing is non-monotonic in the corrected local reruns. 1B stays high and nearly flat; 3B develops a mid-layer dip with an 86% trough. the older 8B run suggested a deeper 70% trough, but that result is pending rerun with the corrected splits.
corrected 1B/3B: 0/200 correct. prompt variables are recoverable; behavior is still broken.
this is the central puzzle. the corrected 1B and 3B runs have linearly decodable root and pattern variables. root identity is high but dips in 3B mid-layers; pattern identity is essentially perfect from the first layer. the information is recoverable and structured, but the current extraction point is the last token of a prompt that explicitly contains the root and pattern.
yet every model outputs "The" for every stimulus. the root and pattern variables are recoverable from hidden states but never translate into the requested output tokens under this prompt setup.
this narrows the Alakeel et al. question considerably. the failure mode is not simply "the prompt variables are absent from hidden states." they are present. the unresolved question is whether those variables reflect morphology-like computation or direct retention of the instruction text. GPT-4o's 97% accuracy on the same task, with the same (or worse) tokenizer, suggests the difference may be in instruction-tuning: how strongly the representation-to-output pathway is shaped during training.
the Alakeel paper concluded "compositional reasoning + instruction-following substitutes for explicit morphological parsing." our results are consistent with a refinement: instruction-following may be what connects recoverable task variables to output behavior. to upgrade that into a morphology claim, the next run needs prompt ablations, span-specific extraction, and controls where root or pattern text is removed or replaced.
"bigger is better" doesn't describe root probing. the corrected local accuracy curve goes from nearly flat (1B) to U-shaped (3B). the older 8B run may deepen the pattern, but it is not part of the corrected comparison yet. this is consistent with the hypothesis from the original research plan:
"if the inflection point is between 1B and 3B, this means explicit morphological injection might only help below ~1B parameters. above that, the model may develop the capability internally , but possibly in a form that linear probes can't access."
the data suggests the inflection point isn't about whether morphological structure is recoverable, but how it is organized. at 1B, root identity is linearly accessible at every layer. at 3B, root identity appears distributed or transformed in mid-layers into a format that logistic regression recovers less cleanly, but the information may still be present since accuracy partially recovers in deeper layers. this looks like a qualitative change in representational organization, not a failure of the model to capture the distinction. (these results are LLaMA-only; a Qwen or Mistral run would test whether the pattern generalizes.)
the corrected result is simpler and more sobering: pattern is basically linearly separable from the first layer in both 1B and 3B. that makes sense because the prompt literally names the pattern. this result is useful, but it is not evidence by itself that the model has performed Arabic root-pattern composition.
possible explanations:
the 8B root-pattern CCA curve (rise to 0.345 at layer 4, then decline to 0.078) shows a pattern consistent with two-phase organization: early layers show increased subspace overlap between root and pattern probe weights, while deeper layers show increasingly separable subspaces. this hump-and-decline shape is absent at both smaller scales.
if this pattern survives a corrected 8B rerun and replicates across model families (Qwen, Mistral), it could be a signature of compositional morphological organization that emerges at larger scale: an intermediate format with higher probe subspace overlap, followed by more separable organization in deeper layers , a two-phase organizational pattern absent at both smaller scales.
all corrected data still uses English zero-shot prompts and last-token hidden states. the "The" output might be a chat-template artifact. testing Arabic prompts, one-shot prompts, and prompt ablations could change the story.
200 stimuli for 20-way classification = 10 samples per class before cross-validation. the corrected split policy avoids impossible folds, but larger stimulus sets and confidence intervals are still needed.
--probe-template, root-span/pattern-span extraction, and masked-root/masked-pattern ablations. this is the main blocker before stronger morphology claims.