ورقة Alakeel et al. (2026) تركت سؤال مفتوح: GPT-4o يوصل 97% في توليد الجذر والوزن العربي على nonce roots مع إنه عنده أسوأ محاذاة tokenizer في الدراسة (17% boundary precision). ALLAM عنده أفضل محاذاة tokenizer، لكنه ينهار لـ 20% على نفس المهمة. جودة الـ tokenizer ما تتنبأ بالكفاءة الصرفية. طيب وش اللي يتنبأ؟
المؤلفون اقترحوا "الاستدلال التركيبي + اتباع التعليمات" كآلية. لكن هذا وصف سلوكي. هذه التجربة تسأل السؤال الـ mechanistic: كيف تبدو التمثيلات الداخلية فعلاً؟
استخدمت ember، وهو inference engine مكتوب من الصفر ويعطي وصول مباشر للـ hidden states بعد كل transformer block، عشان أفحص LLaMA 3.2 1B و LLaMA 3.2 3B على مهمة nonce root-pattern. 20 جذر ثلاثي مخترع من بيانات Alakeel × 10 أوزان عربية = 200 محفز، كلها مكتوبة بحروف لاتينية عشان يكون الـ probing آمن مع ASCII. نتائج 8B من التشغيل الأول مؤرشفة أدناه إلى أن تنعاد على جهاز أقوى. أربع طرق تحليل:
ملاحظة منهجية: الـ probes تقيس المعلومة القابلة للاسترجاع من الـ hidden states، مو المعلومة اللي يستخدمها النموذج سببياً أثناء التوليد. القابلية للفصل الخطي حد أدنى على البنية الموجودة؛ ما تعني إن النموذج يعتمد عليها في المخرج. التشغيل المصحح يستخدم تقسيمات مغلقة مناسبة للمهمة: فحص الجذر يمسك الأوزان خارج التدريب، وفحص الوزن يمسك الجذور خارج التدريب. الصياغة القديمة عن فحص الجذر مع جذور محجوبة كانت غير صالحة لأنها تطلب من المصنف توقع جذور لم يرها في التدريب.
التشغيل المصحح لـ 1B و 3B ما زال يخرج The لكل محفز: 0/200. الـ hidden states تحتفظ بمتغيرات الجذر والوزن المكتوبة صراحة في الـ prompt، لكن هذا ليس دليلاً كافياً بعد على صرف عربي داخلي. الخطوة التالية لازم تفصل بين استرجاع متغيرات الـ prompt وبين الحساب الصرفي فعلاً.
generate_stimuli.py → stimuli/nonce_root_pattern.json (200 stimuli)
ember --probe → activations.npy + correctness.json
train_linear_probe.py → probes.npz (root + pattern accuracy per layer)
cca_analysis.py → cca.npz (layer similarity + disentanglement)
rsa_analysis.py → rsa.npz (representational similarity)
divergence_analysis.py → divergence.npz (correct vs incorrect gap)
plot_results.py --dark → probe_results.png (3x2 figure)
كل الكود في مستودع ember. التشغيل المصحح لـ 1B و 3B تم محلياً. رسم 8B يبقى معروضاً كأرشيف للمقارنة، لكنه لم يُعد بالتقسيم المصحح لأن الجهاز المحلي لا يشغله بثبات.
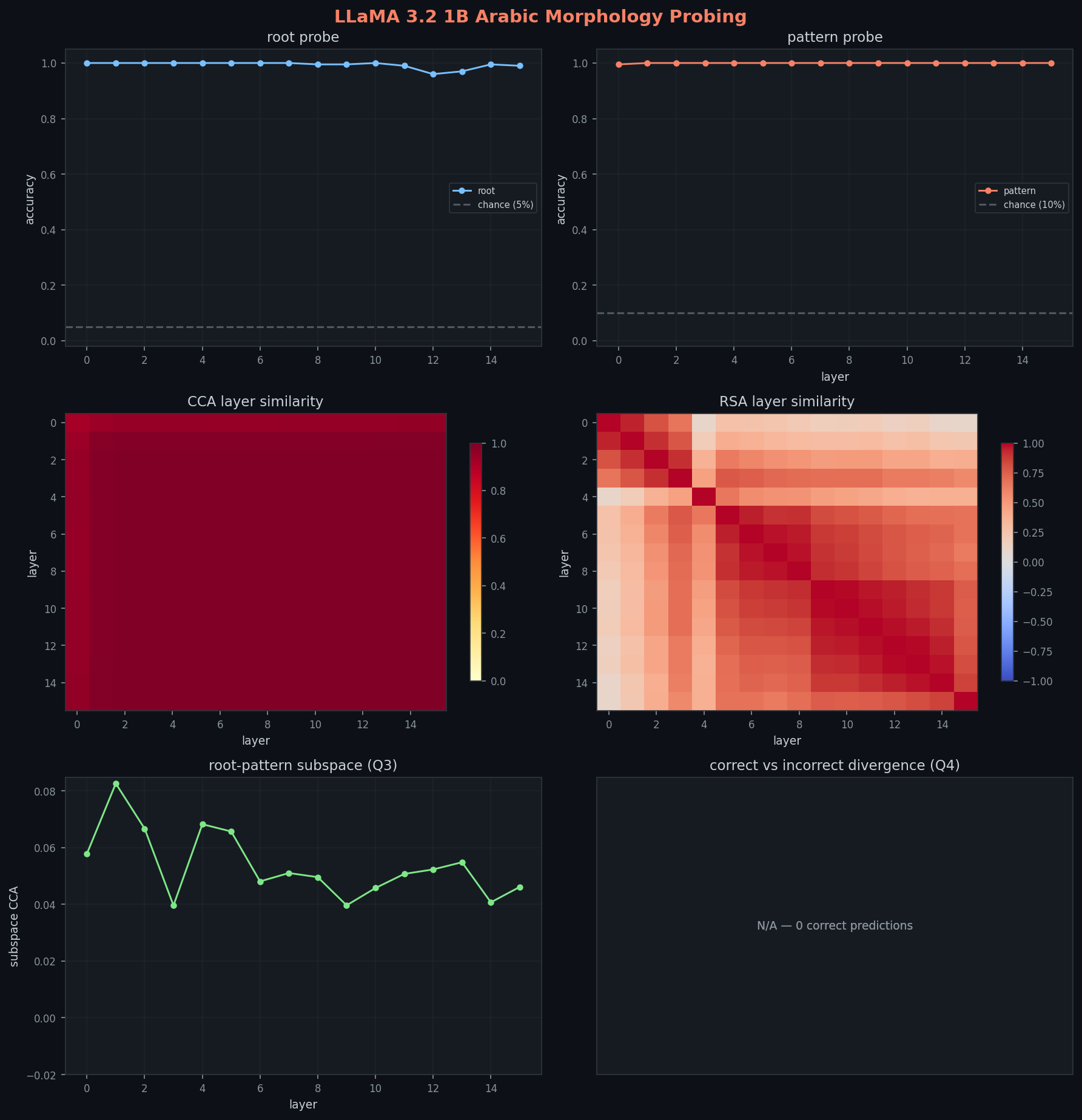
هوية الجذر قابلة للفك بسهولة في كل طبقة (دقة 96-100%، منحنى شبه مسطح). معلومة الجذر تبقى قابلة للاسترجاع خطياً عبر عمق النموذج كامل.
هوية الوزن قابلة للفك خطياً من الطبقة 0 تحت التقسيم المصحح الذي يحجب الجذور: 99.5% في الطبقة 0 ثم 100% بعد ذلك. منحنى "اكتساب الوزن" القديم لا يصمد بعد تصحيح منطق التقسيم.
CCA للتشابه الذاتي يبدأ عند 0.92 (الطبقة 0) ويتشبع بسرعة (0.98 عند الطبقة 1، و 0.999 عند الطبقة 4). التمثيلات تستقر بسرعة. RSA ما زال يكشف انتقالاً هندسياً مبكراً، لكنه لم يعد يفسر كلحظة صيرورة الوزن قابلاً للاسترجاع.
root-pattern subspace CCA منخفض من البداية في الإعداد المصحح، تقريباً بين 0.04 و 0.08 عبر الطبقات، والحد الأدنى 0.040 عند الطبقة 3. أوزان فحص الجذر والوزن منفصلة بقوة من البداية.
هنا تبدأ الغرابة.
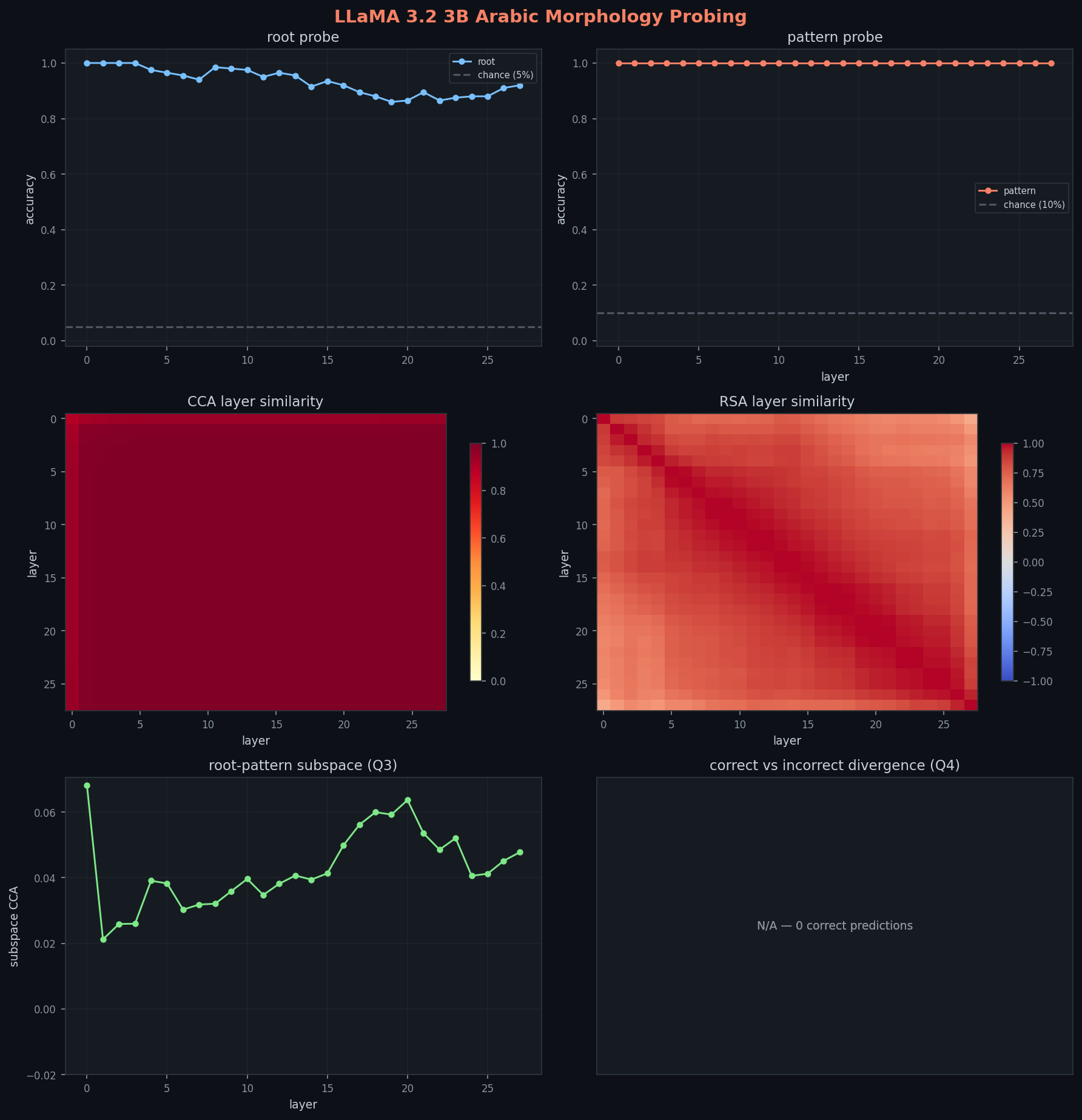
هوية الجذر ما زالت تطور هبوط على شكل U، لكن القاع المصحح أضعف من النسخة الأولى. تبدأ عند 100%، تتآكل في الطبقات الوسطى، تصل القاع عند 86% في الطبقة 19، ثم تتعافى جزئياً إلى 92% في الطبقة الأخيرة. هوية الجذر تصير أقل قابلية للوصول الخطي في الطبقات الوسطى قبل ما ترجع جزئياً في أعمق الكتل.
هوية الوزن مسطحة تماماً عند 100% لكل الطبقات الـ 28. الوزن قابل للفصل خطياً كخاصية سطحية، بدون حاجة للعمق. نموذج 3B يظهر هوية الوزن على فضاء فرعي قابل للوصول الخطي من أول طبقة.
CCA للتشابه الذاتي يبدأ عند 0.889 في الطبقة 0 (أقل شوي من 0.921 في 1B) لكنه يستقر أسرع: 0.977 عند الطبقة 1، و 0.995 عند الطبقة 3. خريطة الحرارة شبه موحدة وفاتحة من الطبقة 4 وطالع. RSA يظهر انتقالات ناعمة ومستمرة بدون الكسر الحاد اللي ظهر في 1B عند الطبقات 3-4.
root-pattern CCA منخفض جداً في التشغيل المصحح: 0.02-0.07 عبر كل الطبقات، والحد الأدنى 0.021 عند الطبقة 1. فضاءات أوزان الـ probe للجذر والوزن تبدو شبه متعامدة تحت CCA في كل طبقة.
3B ما زال عنده أوضح هبوط للجذر. بعد تصحيح التقسيم، 1B لم يعد يظهر منحنى اكتساب للوزن. كلا 1B و 3B يملكان هوية الوزن تقريباً من الطبقة 0. النتيجة الخاصة بـ 3B هي هبوط الجذر: هوية الجذر لا تزال قابلة للاسترجاع، لكنها أقل قابلية للوصول الخطي في منتصف الشبكة. ومع ذلك النموذج ما عنده مخرج عربي.
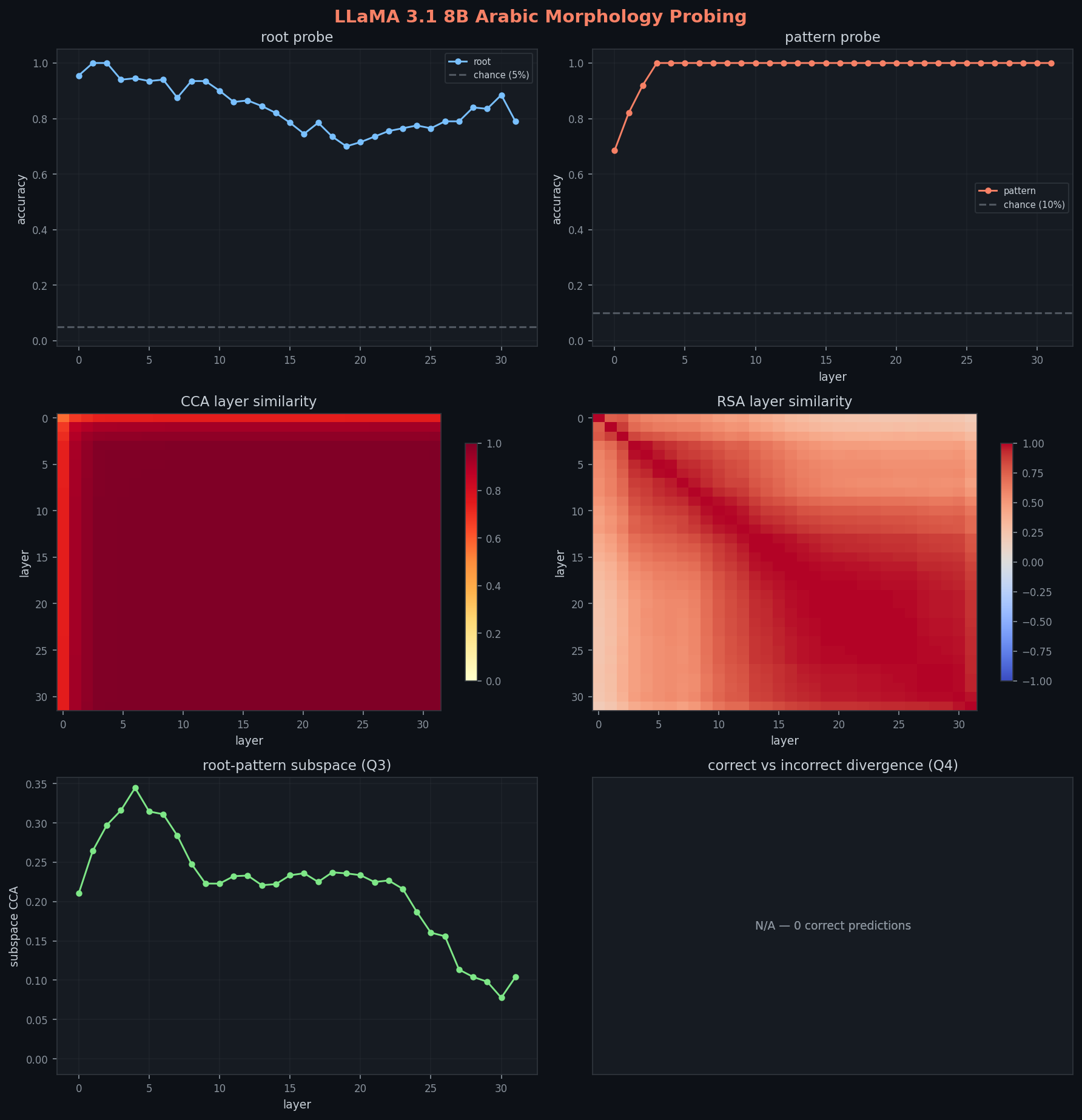
تنبيه أرشيفي: هذا القسم يستخدم ملفات التشغيل الأول لـ 8B ولم يُعد بمنطق التقسيم المصحح. لا تقارن أرقامه الدقيقة مباشرة بنتائج 1B/3B المصححة بعد.
هوية الجذر بدت وكأنها تعمّق هبوط الـ U: بعد قمة قصيرة عند 100% (الطبقة 1)، ينزل عبر 94% ← 88% ← 75% ← ويصل القاع عند 70% في الطبقة 19، ثم يتعافى جزئياً إلى 89%، وبعدها يهبط مرة ثانية إلى 79% في الطبقة الأخيرة. المنحنى مليء بالتفاصيل، مو U نظيف: نزول متعرج مع هبوط ثانوي في النهاية. تعامل مع هذا كإشارة مؤرشفة، لا كاستنتاج تحجيم مصحح.
هوية الوزن بدت كسلم في التشغيل المؤرشف: 69% في الطبقة 0 ← 82% ← 92% ← 100% عند الطبقة 3. لأن نتيجة 1B تغيرت بعد التصحيح، فهذا الادعاء عن 8B ينتظر إعادة التشغيل.
CCA يبدأ منخفض جداً: 0.566 عند الطبقة 0، وهي أكثر تمثيلات مبكرة ضجيجاً بين النماذج. بعدها يصعد: 0.68 (الطبقة 1) ← 0.94 (الطبقة 2) ← 0.99 (الطبقة 4). خريطة الحرارة فيها زاوية سفلية يسارية داكنة بوضوح وتفتح عبر أول 4 طبقات. RSA ارتباط الطبقة 0→1 هو 0.76، ثم يصير ناعماً بين 0.96 و 0.999 بعد ذلك.
root-pattern CCA يعرض أهم منحنى: يرتفع إلى قمة 0.345 عند الطبقة 4، يعني فضاءات الـ probe تظهر تداخلاً أعلى مؤقتاً، ثم ينخفض بثبات إلى 0.078 عند الطبقة 30. هذا نمط متسق مع خلط تمثيلي مبكر ثم فصل لاحق: أول طبقات تظهر تداخل فضاء فرعي أكبر بين أوزان probe للجذر والوزن، بينما الطبقات الأعمق تظهر تنظيماً أكثر انفصالاً. لا 1B (انخفاض رتيب) ولا 3B (شبه مسطح قرب الصفر) يظهران هذا النمط ثنائي المرحلة.
فحص الجذر غير رتيب في التشغيلين المحليين المصححين. 1B يبقى عالياً وشبه مسطح؛ 3B يطور هبوطاً وسطياً بقاع 86%. التشغيل القديم لـ 8B اقترح قاعاً أعمق عند 70%، لكنه ينتظر إعادة التشغيل بالتقسيم المصحح.
التشغيل المصحح لـ 1B/3B: 0/200 صحيحة. متغيرات الـ prompt قابلة للاسترجاع؛ السلوك لا يزال مكسوراً.
هذا هو اللغز الأساسي. التشغيلان المصححان لـ 1B و 3B يملكان متغيرات جذر ووزن قابلة للفك الخطي. هوية الجذر عالية لكنها تهبط في وسط 3B؛ هوية الوزن شبه كاملة من الطبقة الأولى. المعلومة قابلة للاسترجاع ومنظمة، لكن نقطة الاستخراج الحالية هي آخر توكن في prompt يذكر الجذر والوزن صراحة.
ومع ذلك، كل نموذج يرجع نفس المخرج الموحد لكل محفز: The. متغيرات الجذر والوزن قابلة للاسترجاع من الـ hidden states لكنها لا تتحول إلى output tokens المطلوبة تحت هذا الإعداد.
هذا يضيّق سؤال Alakeel et al. كثير. نمط الفشل مو ببساطة "متغيرات الـ prompt غائبة عن الـ hidden states." هي موجودة. السؤال غير المحسوم هو هل هذه المتغيرات تعكس حساباً صرفياً أو مجرد احتفاظ مباشر بنص التعليمات. دقة GPT-4o البالغة 97% على نفس المهمة، وبنفس أو أسوأ tokenizer، تشير إن الفرق قد يكون في instruction-tuning: مدى قوة تشكيل مسار التمثيل إلى المخرج أثناء التدريب.
ورقة Alakeel خلصت إلى أن "الاستدلال التركيبي + اتباع التعليمات يعوض التحليل الصرفي الصريح." نتائجنا متسقة مع صياغة أدق: اتباع التعليمات قد يكون الشيء اللي يربط متغيرات المهمة القابلة للاسترجاع بسلوك المخرج. عشان تتحول هذه إلى دعوى صرفية أقوى، نحتاج prompt ablations، واستخراج من مواضع الجذر والوزن، وتجارب يحذف فيها نص الجذر أو الوزن أو يستبدل.
"الأكبر أفضل" ما يصف فحص الجذر. منحنى الدقة المصحح محلياً ينتقل من شبه مسطح (1B) إلى شكل U (3B). التشغيل القديم لـ 8B قد يعمق النمط، لكنه ليس جزءاً من المقارنة المصححة بعد. هذا متسق مع فرضية الخطة البحثية الأصلية:
"إذا نقطة الانعطاف بين 1B و 3B، فهذا يعني إن الحقن الصرفي الصريح يمكن يساعد فقط تحت حوالي 1B معامل. فوق ذلك، النموذج قد يطور القدرة داخلياً، لكن ربما بصيغة ما تقدر الـ linear probes توصل لها."
البيانات تشير إن نقطة الانعطاف مو عن هل البنية الصرفية قابلة للاسترجاع، بل عن كيف هي منظمة. عند 1B، هوية الجذر قابلة للوصول الخطي في كل طبقة. عند 3B، هوية الجذر تبدو موزعة أو متحولة في الطبقات الوسطى إلى صيغة يسترجعها logistic regression بدرجة أضعف، لكن المعلومة قد تكون ما زالت موجودة لأن الدقة تتعافى جزئياً في الطبقات الأعمق. هذا يبدو كتغير نوعي في التنظيم التمثيلي، مو فشل من النموذج في التقاط الفرق. هذه النتائج خاصة بـ LLaMA حالياً. تشغيل Qwen أو Mistral يختبر هل النمط يعمم.
النتيجة المصححة أبسط وأكثر تحفظاً: الوزن قابل للفصل الخطي من أول طبقة تقريباً في 1B و 3B. هذا منطقي لأن الـ prompt يذكر اسم الوزن صراحة. النتيجة مفيدة، لكنها لا تثبت لوحدها أن النموذج نفذ تركيباً صرفياً عربياً.
تفسيرات ممكنة:
منحنى root-pattern CCA في 8B (ارتفاع إلى 0.345 عند الطبقة 4 ثم هبوط إلى 0.078) يظهر نمطاً متسقاً مع تنظيم ثنائي المرحلة: الطبقات المبكرة تعرض تداخلاً أعلى بين فضاءات أوزان probe للجذر والوزن، بينما الطبقات الأعمق تعرض فضاءات أكثر انفصالاً. شكل القمة ثم الهبوط غائب عند الحجمين الأصغر.
إذا صمد هذا النمط بعد إعادة تشغيل 8B بالتقسيم المصحح وتكرر عبر عوائل نماذج ثانية (Qwen، Mistral)، قد يكون توقيعاً لتنظيم صرفي تركيبي يظهر عند حجم أكبر: صيغة وسيطة بتداخل فضاء فرعي أعلى، ثم تنظيم أكثر انفصالاً في الطبقات العميقة. نمط تنظيمي ثنائي المرحلة غائب عند الحجمين الأصغر.
كل البيانات المصححة ما زالت تستخدم English zero-shot prompts وآخر توكن في الـ prompt. المخرج الموحد The قد يكون أثر chat-template؛ اختبار Arabic prompts و one-shot و prompt ablations ممكن يغير القصة.
200 محفز لتصنيف من 20 فئة = 10 عينات لكل فئة قبل cross-validation. منطق التقسيم المصحح يتجنب الطيات المستحيلة، لكن ما زلنا نحتاج محفزات أكثر وفواصل ثقة.
--probe-template، واستخراج من موضع الجذر والوزن، وتجارب تحجب الجذر أو الوزن. هذا هو العائق الأساسي قبل دعوى صرفية أقوى.