this note summarizes a preliminary layerwise probe run over Arabic nonce root-pattern stimuli. the question is narrow: are root and pattern labels linearly recoverable from saved hidden states across LLaMA, Qwen, and one completed Gemma model?
the answer is descriptive, not behavioral. these probes measure recoverability from hidden states under this dataset and split policy. they do not show that a model understands Arabic morphology, generates correct forms, or causally uses the probed features.
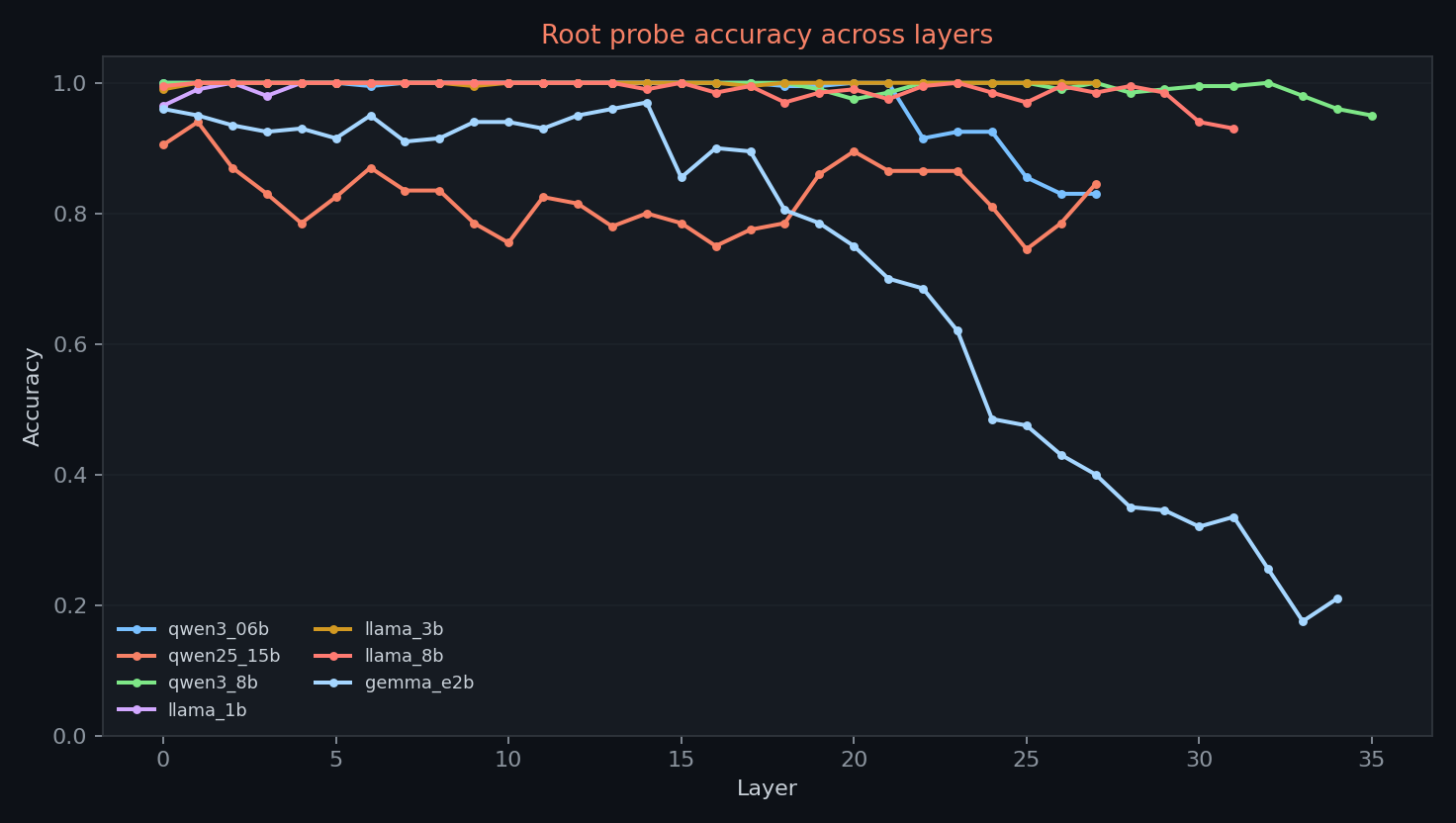
treat this as a measurement note. pattern labels are saturated in this setup; root labels carry most of the visible variation. Gemma E2B later layers need extra skepticism because golden-logit validation reached only cosine ~0.87 against llama.cpp.
hidden states were extracted with ember using
--probe over stimuli/nonce_root_pattern.json.
the run crossed 20 nonce roots with 10 Arabic morphological patterns,
yielding 200 stimuli. this page uses the saved artifacts from
artifacts/morphology_runs/20260613_022050; extraction
and probe training were not rerun for this note.
pattern-heldout.root-heldout.
the probe files also contain scalar split_policy=random.
in this note, that scalar field is treated as a recording artifact:
the task-specific root_split, pattern_split,
and split_policy_json fields take precedence.
peak entries are formatted as layer / score. layer
numbers are zero-based NPZ array indices. when layers tie for peak
score, the first peak layer is reported.
| model | family | root peak | root final | pattern peak | pattern final |
|---|---|---|---|---|---|
qwen3_06b | Qwen 0.6B | 0 / 1.000 | 0.830 | 0 / 1.000 | 1.000 |
qwen25_15b | Qwen 1.5B | 1 / 0.940 | 0.845 | 0 / 1.000 | 1.000 |
qwen3_8b | Qwen 8B | 0 / 1.000 | 0.950 | 0 / 1.000 | 1.000 |
llama_1b | LLaMA 1B | 2 / 1.000 | 1.000 | 1 / 1.000 | 1.000 |
llama_3b | LLaMA 3B | 1 / 1.000 | 1.000 | 0 / 1.000 | 1.000 |
llama_8b | LLaMA 8B | 1 / 1.000 | 0.930 | 1 / 1.000 | 1.000 |
gemma_e2b | Gemma E2B | 14 / 0.970 | 0.210 | 1 / 1.000 | 1.000 |
root labels are the more informative task in this run because they vary across models and layers. five models reach a peak root score of 1.000. Qwen 1.5B peaks lower at 0.940, and Gemma E2B peaks at 0.970.
final-layer drops are concentrated in root classification. all three Qwen models end below their peak, LLaMA 8B ends below peak, and Gemma E2B shows the largest drop. LLaMA 1B and LLaMA 3B remain saturated at the final layer.
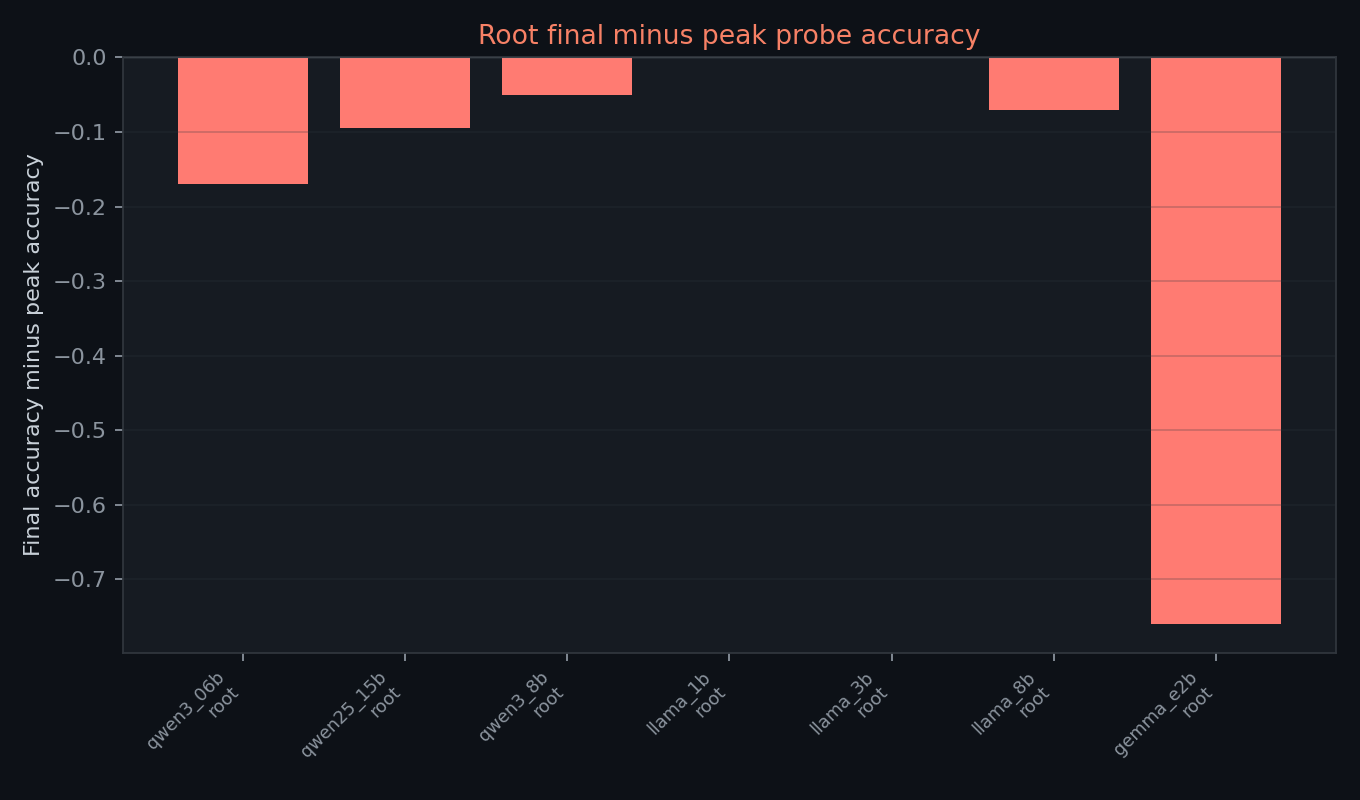
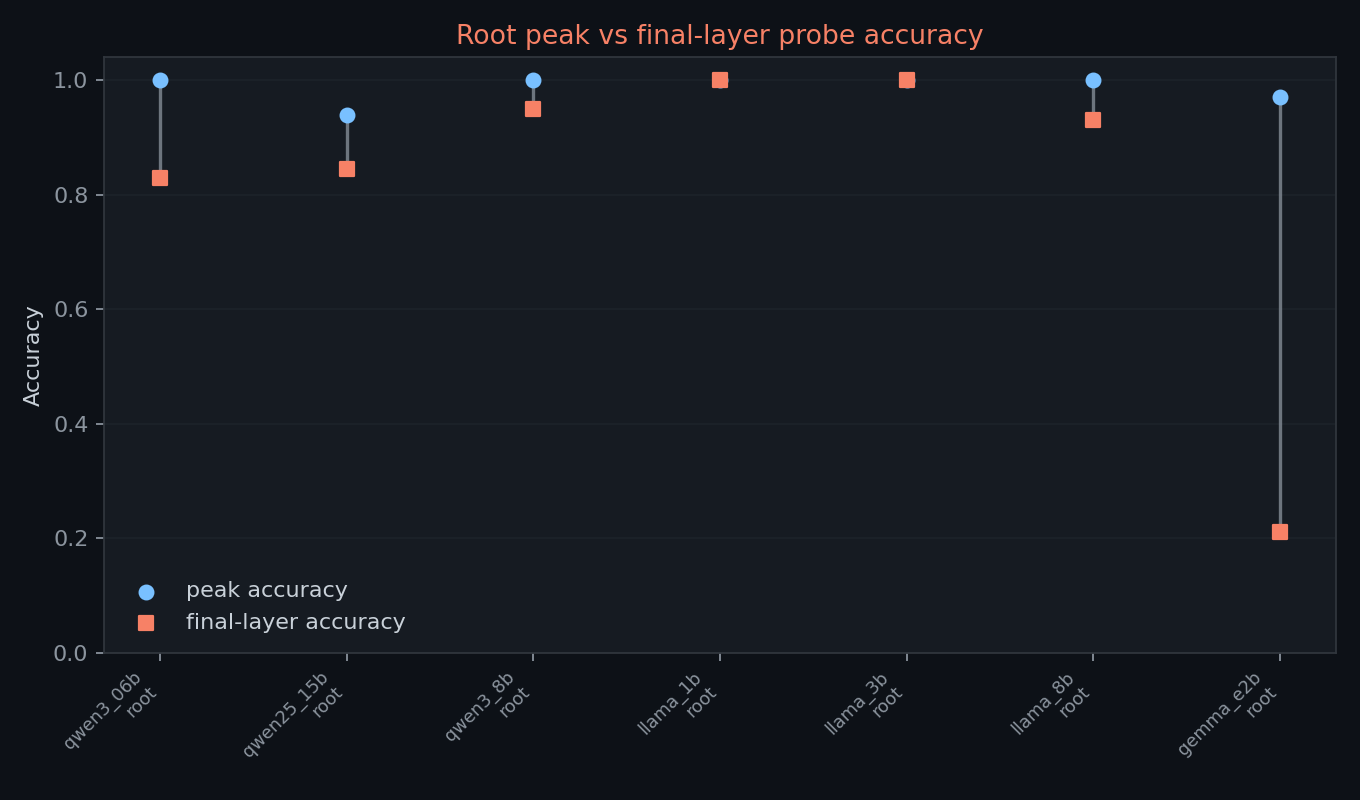
the LLaMA-vs-Qwen final-layer contrast is the most interesting cross-family signal in the table: LLaMA 1B and 3B stay saturated, while all Qwen models drop below peak. this is hypothesis-generating only. the current run does not establish why the contrast appears or whether it survives reruns.
Gemma E2B has the latest root peak at layer 14 and the largest final-layer root drop, from 0.970 to 0.210. that is visually distinctive, but it should not be read as a clean Gemma-specific representational result.
the Gemma E2B golden-logit validation reached only cosine ~0.87 against llama.cpp, with gradual layerwise drift from layer 5 onward. later hidden states may therefore be affected by numerical accumulation in the implementation rather than only by model-internal morphology representations. the layer 14 root peak and final-layer drop are potentially confounded by this.
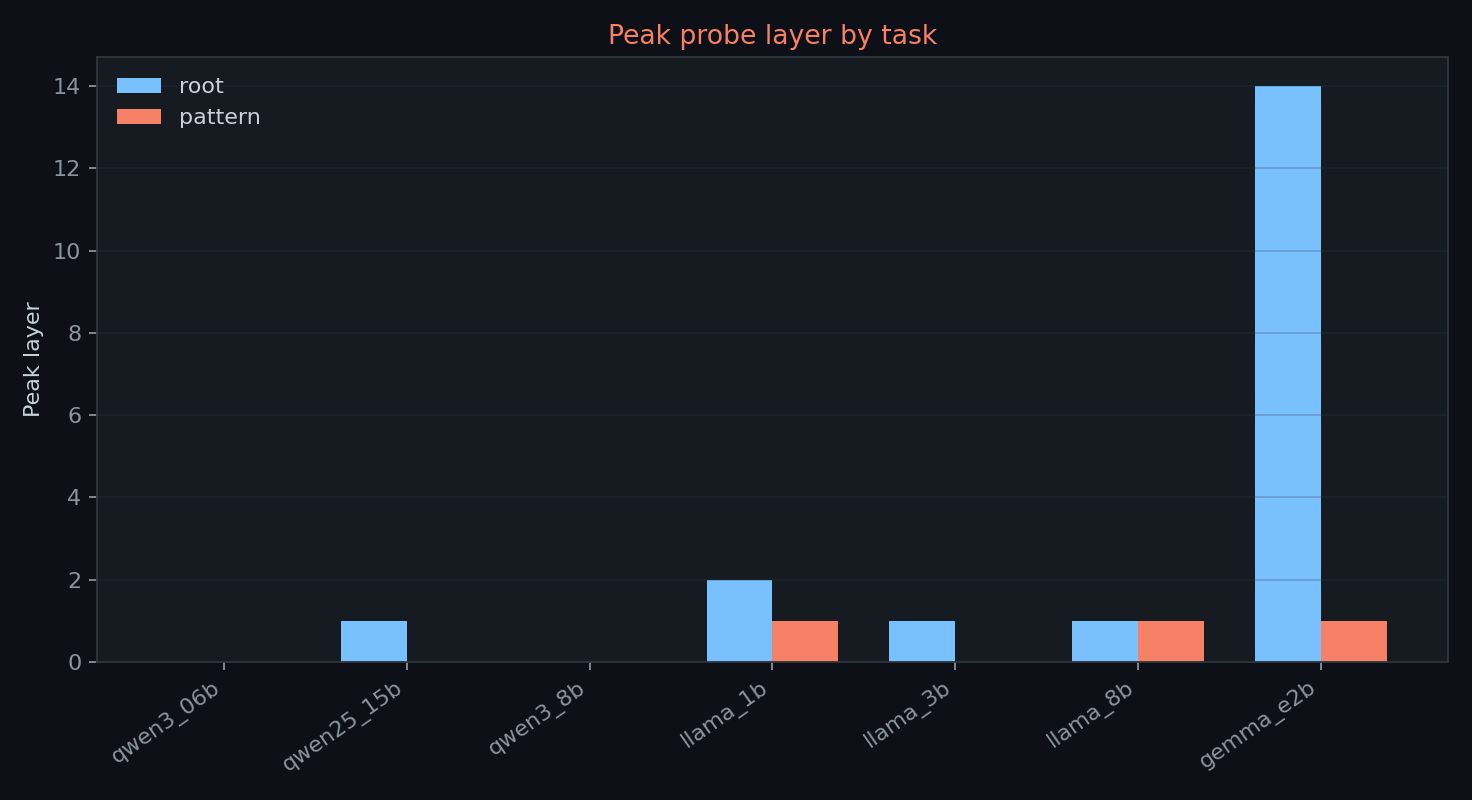
pattern labels are linearly recoverable at ceiling for all seven completed models. every model reaches a peak score of 1.000, and every model also has a final-layer score of 1.000.
this is a strong interpretability limit. pattern is only a 10-way classification task here, and ceiling performance leaves little room to interpret family differences, scale differences, or layer timing. the stimuli may simply be too easy for this task under the current probe setup. pattern results should not be used to support cross-family or scale comparisons in this run.
the RSA, CCA, and PCA figures are included as exploratory checks, not primary evidence. the saved geometry files are within-model matrices; they are not pairwise cross-model CCA or RSA.
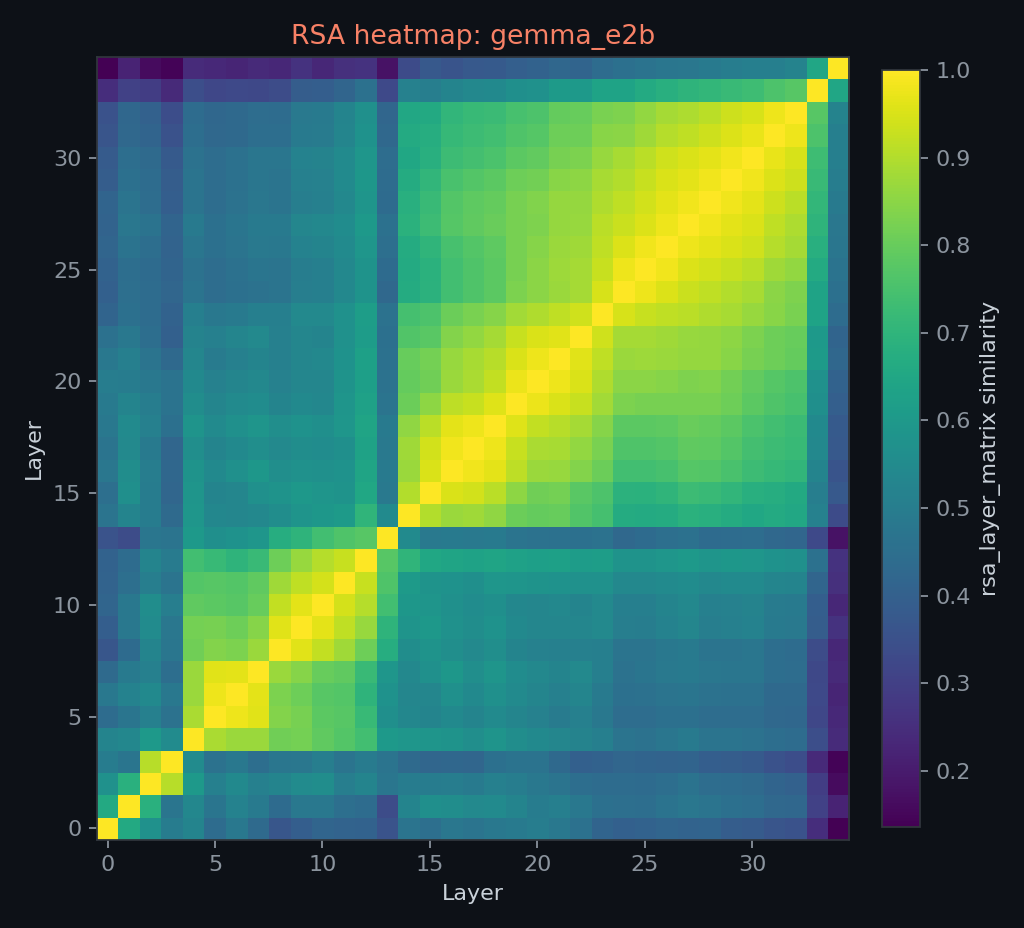
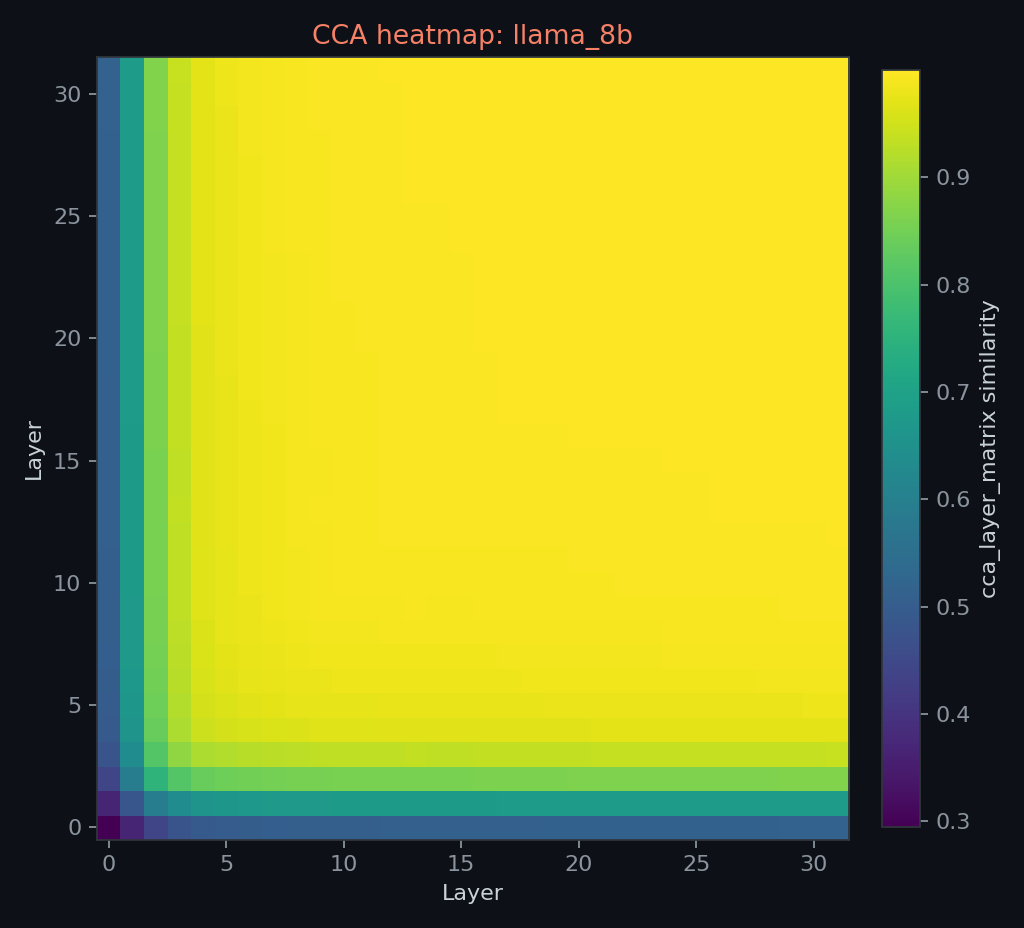
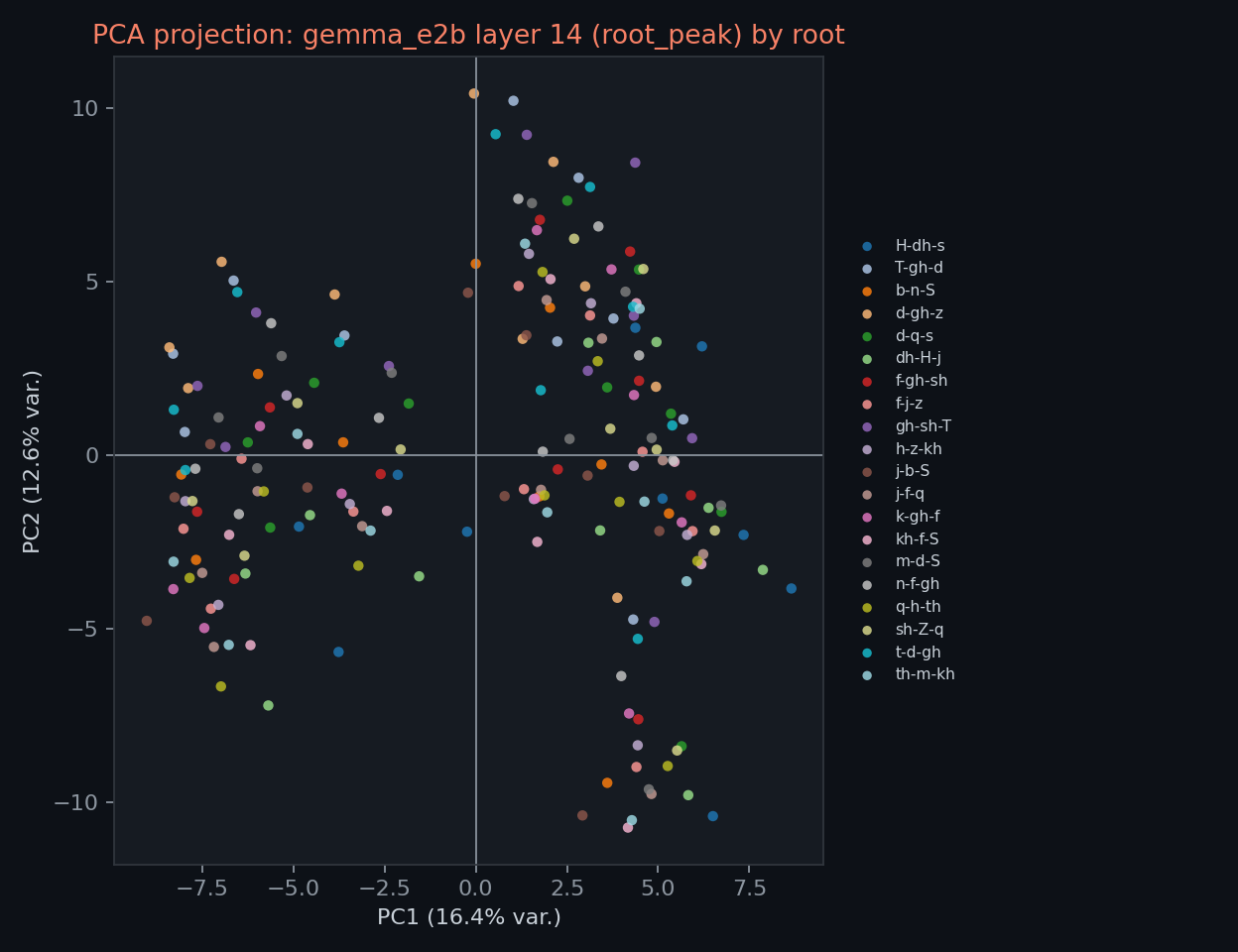
the PCA projection is illustrative only. root silhouette scores in the PCA package are weak, so this figure should not be used to claim strong clustering or linguistic competence.