llama and qwen3 both landed golden-logit parity against llama.cpp within a few days each. cosine ~0.9998, top-1 matched across english and arabic prompts, the pipeline was clean. gemma 4 was supposed to be the third one.
the model loaded. dimensions checked out, 35 layers, hidden dim 1536, vocab 262144. the forward pass ran. didn't crash. the logits weren't nan. first prompt i tried was arabic, "كتب الطالب".
the output was english. sometimes japanese. entropy 3.6 out of 12.48, nearly uniform. llama.cpp on the same prompt had entropy 0.06. the logits were so flat that the model couldn't pick a token with any confidence. it just... emitted things. coherent things, wrong language, like a multilingual slot machine.
this is what it took to figure out why.
this matters because it set expectations. llama 3.2 1b hit cosine 0.99947–0.99992 across 7 prompts, top-1 matched every time, top-5 overlap was 5/5, top-10 was 9–10/10. max abs diff 0.36. the bugs along the way were real but diagnosable, kv cache recreated every decode step, entire token sequence passed during decode instead of just the new token, logits sliced with embed_dim instead of vocab_size. all fixable in an afternoon each.
qwen3 0.6b was similar. cosine 0.99955–0.99979, all top-1 match, max abs diff 0.59. arabic prompts dropped slightly, 0.99955 vs 0.99975, but still matched. different tokenizer, qk norm, slightly different rope config, but the architecture was close enough to llama's that the port was mostly swapping metadata.
| prompt | llama cosine | qwen3 cosine |
|---|---|---|
| "Hello" | 0.99991 | — |
| "Hello world" | 0.99986 | 0.99979 |
| "كتب الطالب" | 0.99984 | 0.99974 |
| "الطالبات كتبن" | — | 0.99955 |
llama: 7 prompts, max abs diff 0.36, mean 0.040 · qwen3: 5 prompts, max abs diff 0.59, mean 0.079
after two clean ports i had exactly the wrong amount of confidence for gemma 4. i expected a weekend. it took two weeks and the answer is still not really satisfying.
gemma 4 is weirder than llama. per-layer embeddings (ple), global projection layers, layer output scales, a separate rope_freqs.weight tensor for partial rope, bf16 weights in the gguf, tied embeddings for the lm head, final logit softcapping at 30.0. the block layout has three sub-pathways per layer instead of two. none of this is exotic, exactly, but there are more places to get things wrong.
the shapes matched. the model ran. the logits were flat garbage. "كتب الطالب" went in. english came out. sometimes japanese. i started trying things.
each of these was a hypothesis. build, run golden-logit comparison against llama.cpp, check cosine. most took a few hours. some took a day.
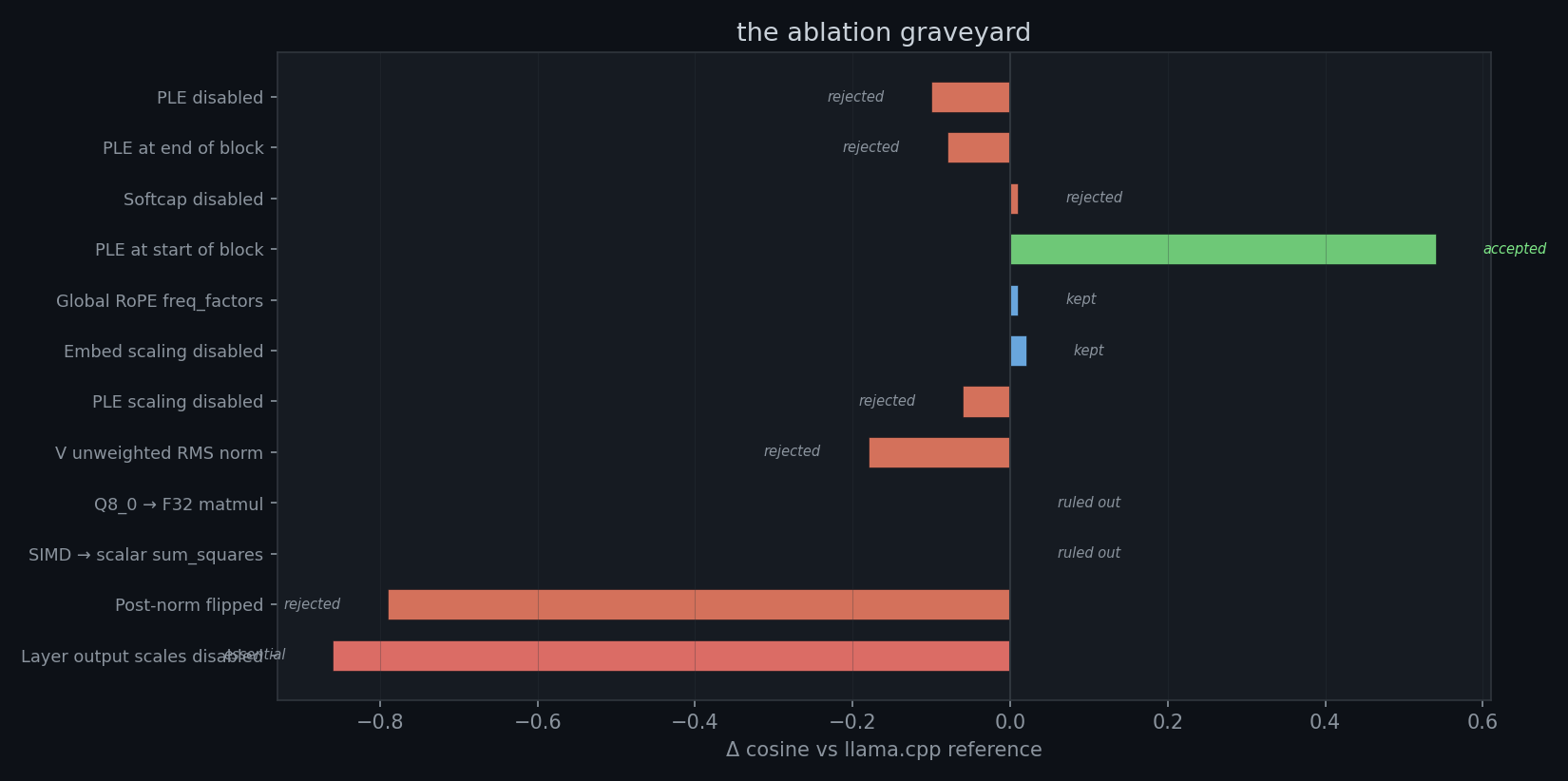
| what i changed | cosine vs llama.cpp | verdict |
|---|---|---|
| disable ple entirely | 0.08 | nope |
| disable final softcap | no real change | nope |
| move ple to end of block | 0.10 | nope |
| move ple to start of block | 0.72 | this one helped |
| disable embedding scaling (sqrt(1536)) | 0.86 | minor, kept it |
| disable layer output scales | −0.54 | essential, don't touch |
| unweighted rms norm on v | 0.70 (worse) | nope |
| flip post-norm ordering | 0.92 → 0.13 | nope, and concerning |
| scale ple by sqrt(per_layer_dim) | 0.88 → 0.82 | nope |
| replace q8_0 matmul with f32 | identical | not quantization |
| force scalar sum_squares (no simd) | identical | not simd |
| check rmsnorm weights vs gguf | cosine 1.0, diff 0.0 | not weight loading |
| add rope freq_factors to global layers | minimal change | correct, kept it |
the ple placement move from end-of-block to start-of-block was the first real jump, 0.10 to 0.72. but 0.72 is still wrong. a cosine of 0.72 on a vocabulary of 262k tokens means the model is in roughly the right neighborhood but not producing the right answer.
the post-norm ordering one was interesting in a bad way. llama.cpp applies norm before the residual add, that's the standard transformer formulation. when i flipped ember to match, cosine dropped from 0.92 to 0.13. that meant something else in the block was wrong in the opposite direction, and the two errors were accidentally cancelling. this kind of thing makes you question every assumption you have about the code.
after maybe ten rejected hypotheses the pattern was becoming visible. this wasn't going to be one clean bug with a satisfying one-line fix.
at one point cosine improved from 0.84 to 0.92. i thought i was making progress. top-5 overlap was still zero. top-1 was still wrong. the model was still producing english from arabic.
what cosine measures: the angle between two vectors in 262k-dimensional space. a vector where most entries are medium-valued (flat distribution) can have high cosine with a sharply peaked vector if they point in roughly the same direction. softmax doesn't care about the angle, it cares about the relative differences between entries. so cosine can go up while the model stays broken.
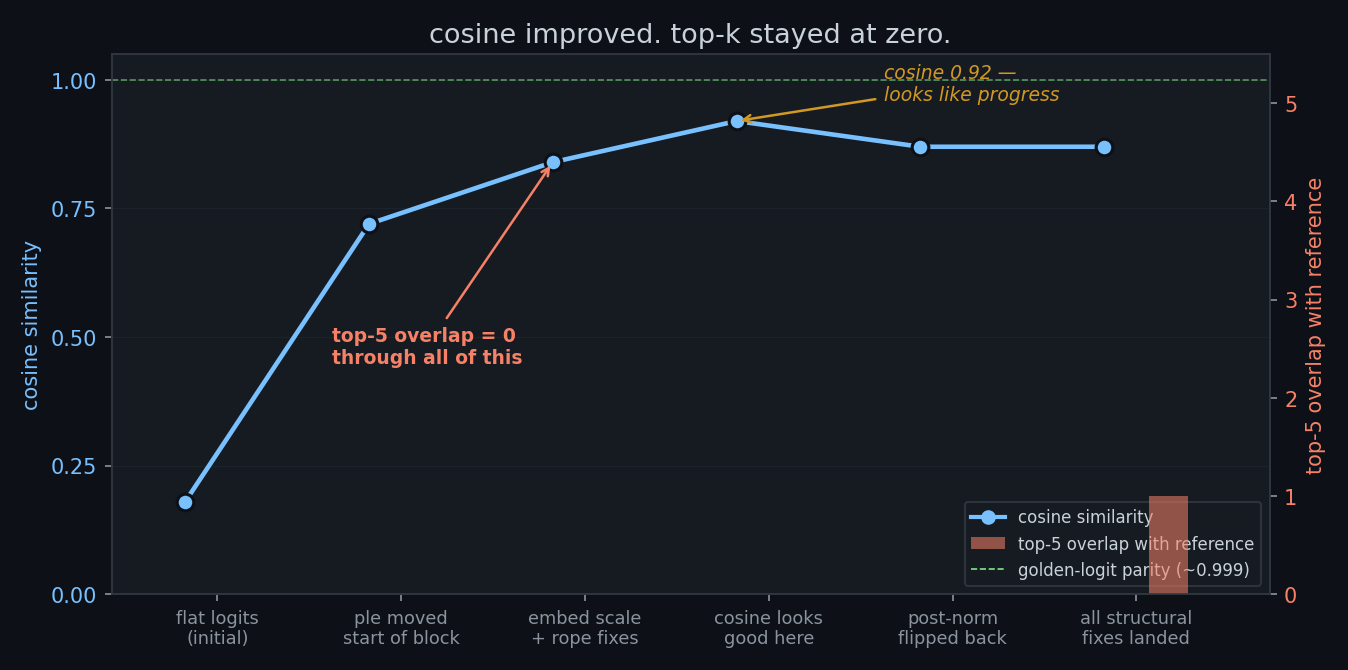
the metric that actually tracks correctness is top-k overlap with the reference. if llama.cpp's top-5 tokens don't appear in ember's top-5, cosine 0.99 is meaningless. you're sampling from a different distribution.
i burned at least two days chasing cosine improvements that turned out to be noise. don't do that. watch top-k.
at some point comparing final logits wasn't giving enough signal. a final cosine of 0.87 could mean one layer is catastrophically wrong, or every layer is slightly wrong and the errors compound. you can't tell from the output alone.
so i patched llama.cpp to dump per-layer hidden states. three source files modified, llama-graph.h, llama-graph.cpp, llama-context.cpp, plus gemma4.cpp to push each block output onto a vector. compiled a small c++ helper that evaluates a bos token and writes 35 × 1536 floats to a binary file. ember already had a --dump-layers flag from earlier work, same format. python script reads both, computes per-layer cosine and l2 norms.
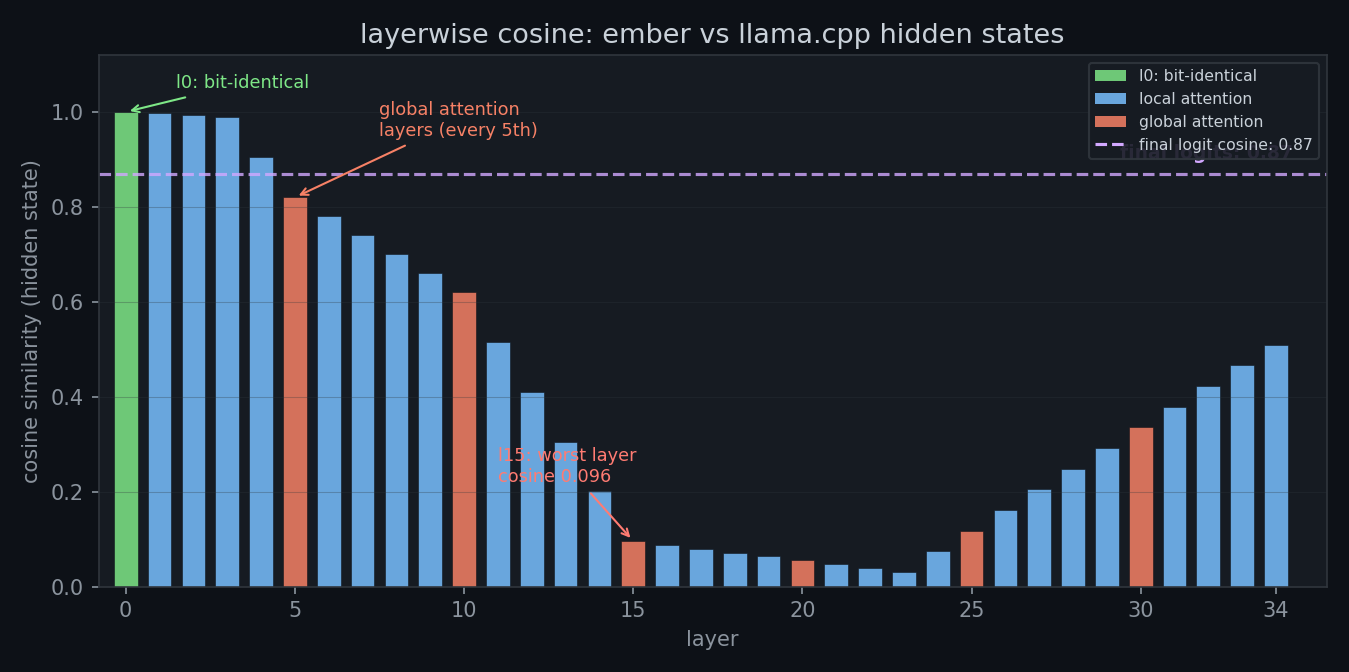
three things stood out.
first: layer 0 is bit-identical. the attn_norm output has the same floating-point values in both implementations. that means the embedding lookup, tokenization, and initial normalization are all correct. the pipeline starts exactly where it should.
second: the divergence is gradual. there's no single cliff where cosine drops from 0.99 to 0.10 in one layer. each layer loses a little more alignment. the global attention layers hit harder, every 5th layer has head_dim 512 instead of 256 and a different rope theta, so there's more surface area for numerical differences to accumulate.
third: the lm head recovers cosine from 0.51 to 0.87. the final hidden state is pretty divergent from llama.cpp's, but after multiplying by the tied token_embd.weight matrix, the resulting logit vector happens to point more toward the reference. this is not the model "getting better", it's an artefact of the projection matrix. and it's part of why cosine on final logits was misleading: it looked better than the hidden states actually were.
with the layerwise pipeline working, i could actually see which changes helped and which didn't. the structural bugs, where ember was doing a fundamentally different computation from llama.cpp, were loud. fixing one moved cosine visibly.
ple pathway. gemma's per-layer embedding uses blk.{i}.inp_gate.weight (1536 → 256) and blk.{i}.proj.weight (256 → 1536). the proj weight was loaded with a transpose. additionally, there's a global ple projection: per_layer_model_proj [1536, 8960] combined with raw ple lookup, scaled by 1/sqrt(2). the global proj is stored as bf16 in the gguf, ember had no bf16 loader. added one.
block layout. the order of operations per block had to exactly match llama.cpp's graph: attn_norm → attention → post_attn_norm → residual, then ffn_norm → gate/gelu/up/down → post_ffn_norm → residual, then ple → post_ple_norm → residual, then multiply by layer_output_scale. getting one norm in the wrong place shifts everything downstream.
embedding scaling. token embeddings get multiplied by sqrt(1536). this is in the reference, i had missed it. minor impact on cosine (~0.02) but it's correct.
layer output scales. each block has a learned scalar with geometric mean ~0.42. disabling this gave cosine negative 0.54. not optional.
gelu. both mlp and ple use the tanh approximation (ggml_gelu), not exact gelu. this matters for matching numerics.
rope freq_factors. the rope_freqs.weight tensor (256 values) controls partial rope: 64 frequency pairs get rotation, 192 pairs get identity (factor ~1e30 → freq = 0). this is different from llama where all pairs get rotated.
final softcap. gguf metadata key gemma4.final_logit_softcapping says 30.0. i had it hardcoded to 15.0. halved the effective range.
tied embeddings. no separate output.weight, the lm head reuses token_embd.weight. path is hidden → output_norm → tied logits → softcap(30.0). not complicated, just different from llama.
| fix | rough impact |
|---|---|
| ple placement at start of block | cosine 0.10 → 0.72 |
| global ple projection + bf16 loader | correct pre-projection |
| block layout aligned to llama.cpp | operations match |
| embedding scale sqrt(1536) | ~0.02 |
| layer output scales | essential (disabled → −0.54) |
| gelu tanh approximation | matches ggml_gelu |
| rope freq_factors | partial rope correct |
| final softcap 30.0 | doubled effective range |
| tied embeddings | no missing output.weight |
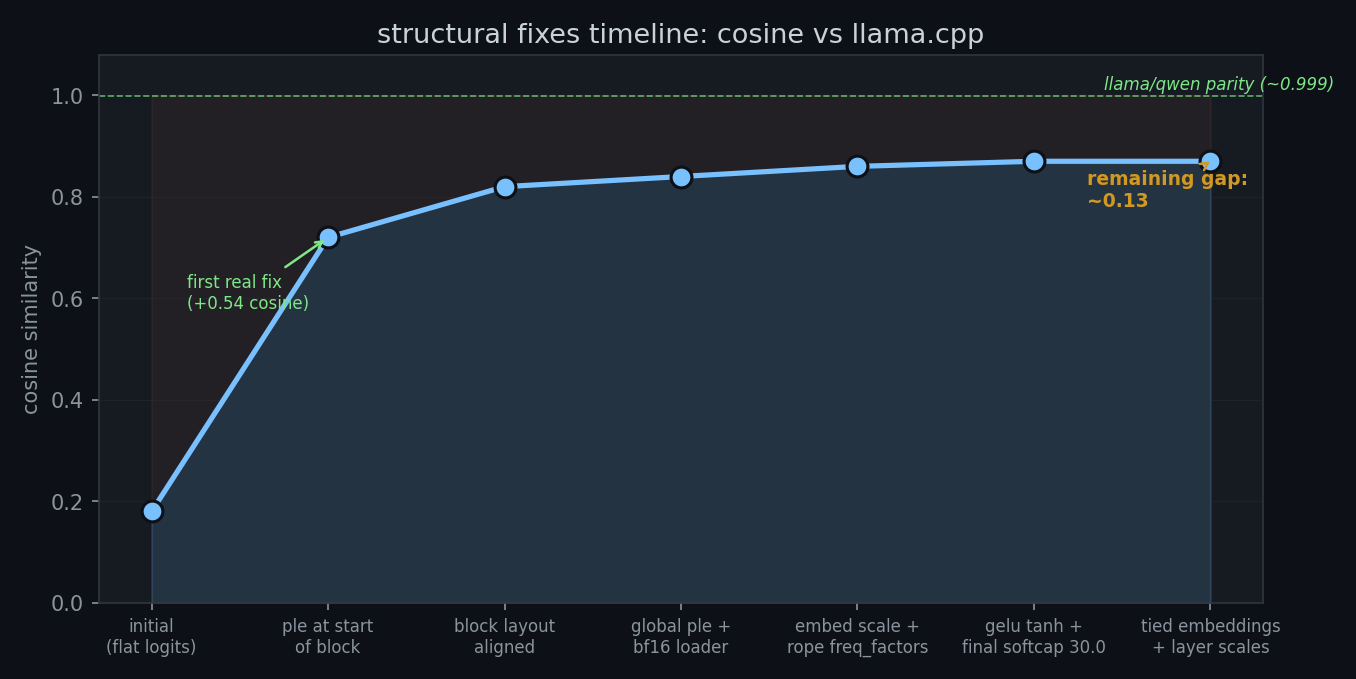
after all of these landed, final logit cosine settled around 0.87. the model produced coherent english. arabic still diverged, but it was no longer producing japanese from arabic prompts. the remaining gap was about 0.13.
at this point i had fixed every structural mismatch i could find. the pipeline started bit-identical at layer 0. rmsnorm was verified six ways: manual computation matched the backend, weights matched gguf exactly (cosine 1.0, l2 diff 0.0), simd sum_squares matched scalar, and 26 tests passed. the code was correct as far as i could tell.
and the final cosine was still 0.87.
what i eventually understood, by dumping and comparing l4 attn_norm inputs from both implementations, was that the remaining gap isn't a bug. it's numerical sensitivity.
gemma 4's rmsnorm weights are just large. the max value in some layers is over 200. that means even a tiny angular difference in the input, from gelu precision, matmul accumulation order, attention softmax numerics, whatever, gets amplified into a visible divergence. this does not look like a simple bug in Rust, C, or the high-level implementation. it's a property of the model architecture interacting with floating-point non-associativity.
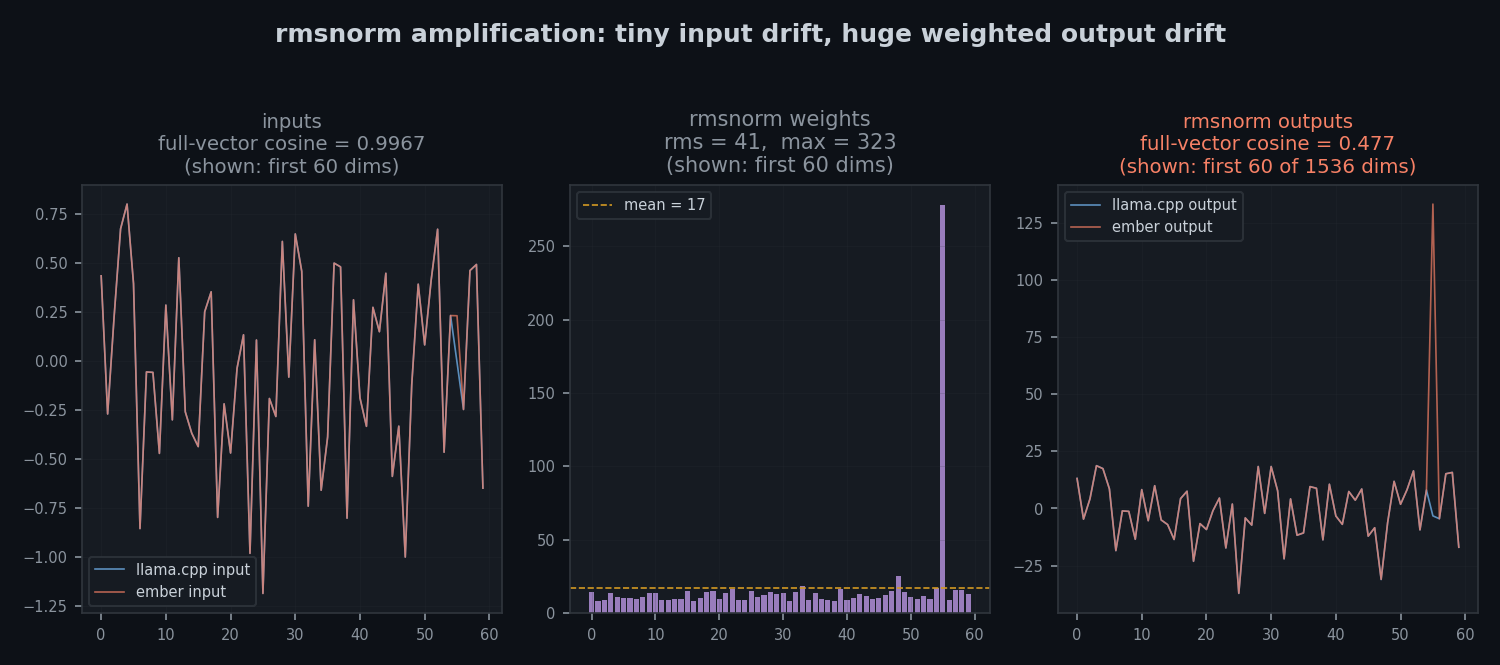
closing the remaining gap would likely require matching llama.cpp's numerical execution path much more closely: accumulation order, approximations, quantized matmul details, and attention/softmax precision. the practical answer is: after structural bugs are resolved, cosine ~0.87 with coherent output is a reasonable stopping point, matching llama.cpp's structure and behavior without cloning its exact numerical execution path.
i spent about a week on this conclusion and i'm still not entirely happy with it. but the evidence is consistent. l0 is bit-identical. the divergence is gradual, not catastrophic. rmsnorm weights are the amplifier. i couldn't find evidence of a remaining structural mismatch.
target/release/ember --model gemma-4-E2B-it-Q8_0.gguf --arch gemma4 \
--prompt "Hello world" --max-seq-len 128 --temperature 0 \
--dump-logits /tmp/test.npy
python3 -c "
import numpy as np
e = np.load('/tmp/test.npy')[0]
r = np.load('artifacts/golden_logits_gemma/llamacpp_logits.npz')['logits'][0]
cos = np.dot(e,r)/(np.linalg.norm(e)*np.linalg.norm(r))
print(f'cosine={cos:.6f}')
"# requires patched llama.cpp (see docs/layer-dump-tooling.md)
# 1. dump llama.cpp layers
./dump_llamacpp_layers gemma-4-E2B-it-Q8_0.gguf "" llama_layers.bin 16
# 2. dump ember layers
target/release/ember --model gemma-4-E2B-it-Q8_0.gguf --arch gemma4 \
--prompt "" --max-seq-len 16 --temperature 0 \
--dump-layers ember_layers.bin
# 3. compare
python3 scripts/compare_layer_dumps.py \
--ember ember_layers.bin --reference llama_layers.bin \
--layers 35 --hidden-size 1536 \
--out-md report.md --out-json report.jsoncargo test --lib| model | prompts | cosine range | top-1 match | max abs diff |
|---|---|---|---|---|
| llama 3.2 1b | 7 | 0.99947–0.99992 | yes | 0.36 |
| qwen3 0.6b | 5 | 0.99955–0.99979 | yes | 0.59 |
| gemma 4 e2b (early, flat logits) | 1 | 0.18 | no | — |
| gemma 4 e2b (intermediate) | 1 | 0.67 | no | 31.7 |
| gemma 4 e2b (after fixes) | 1 | ~0.87 | no | — |
| file | what |
|---|---|
| src/gemma4.rs | full gemma 4 forward pass (~1980 lines) |
| src/tensor.rs | compute_rope_freqs, rms_norm, softmax |
| src/loader.rs | gguf parsing, bf16 (type 30) |
| src/simd.rs | avx2/neon kernels, sum_squares check |
| src/quant.rs | q8_0 dequantization |
| tools/dump_llamacpp_layers.cpp | llama.cpp layer dump helper |
| scripts/compare_layer_dumps.py | layerwise comparison |